Introducción
¿Qué es el riesgo de crédito?
¿Qué es una scorecard de crédito?

Estado del arte
Objetivo del trabajo
Metodología
Análisis Exploratorio y Preprocesamiento de los Datos
Depuración inicial
Estadísticas de las variables numéricas
Estadísticas de las variables categóricas
Imputación de nulos
Matriz de correlación
Balanceo de los datos
Codificación de variables
Hipótesis del conjunto de datos
Modelo de referencia: Regresión Logística
Modelo de Redes Neuronales Artificiales
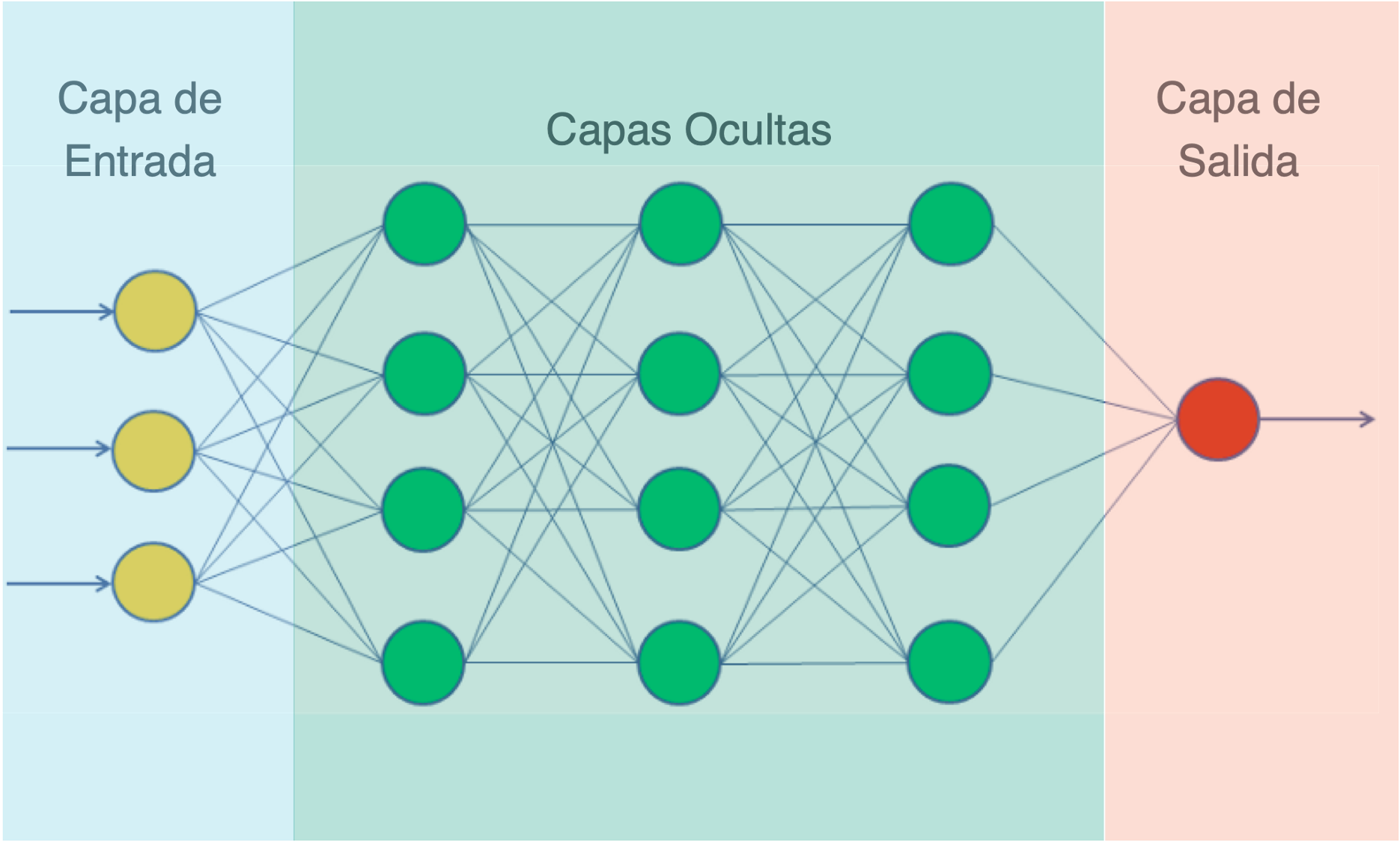
Arquitectura del modelo

Exploración con otros conjuntos de datos
Utilizaremos otros datos, esta vez escalados con el método SMOTE, como técnica de oversampling y aumentar la cantidad de muestras en la clase minoritaria generando nuevos datos sintéticos.
history = modelo_n.fit(
X_balanced,
y_balanced,
validation_split=0.2,
epochs=100,
batch_size=32,
callbacks=[early_stopping, reduce_lr],
verbose=1
)