Hacia una Colombia Libre de Violencia Sexual: Análisis y Acción
Para el desarrollo del proyecto en la materia de gestión de proyectos para analítica, se seleccionó un data frame que relaciona información sobre violaciones sexuales desde el 01 de enero del año 2010 al 31 de Mayo del año 2023. Por lo tanto, este conjunto de datos consta de 290.362 datos recolectados y 9 columnas principales que representan las características de cada delito. Este se puede buscar en la siguiente ruta: https://www.datos.gov.co/Seguridad-y-Defensa/Visual-sexuales-PolNal/9dv7-nexx
Por otra parte, es importante utilizar las seis fases de la metodología CRIPS-DM, con el objetivo de planificar y organizar correctamente la elaboración del proyecto.
FASE 1: COMPRENSION DEL NEGOCIO
Colombia ha enfrentado históricamente problemas relacionados con las violaciones y la violencia sexual. Estos incidentes no solo tienen un impacto devastador en las víctimas y sus familias, sino que también debilitaban la confianza en las instituciones y perpetúan patrones de discriminación y desigualdad. La necesidad de abordar este problema es crítica en términos de derechos humanos, igualdad de género y seguridad pública.
El objetivo principal de este proyecto es analizar una base de datos sobre violaciones en Colombia para arrojar luz sobre las tendencias, patrones geográficos y características demográficas de estos incidentes. A través de este análisis, se busca proporcionar una base sólida para la toma de decisiones informadas por parte de las autoridades y los actores involucrados en la prevención y mitigación de la violencia sexual en Colombia.
El proyecto agrega valor de diversas maneras:
FASE 2: ESTUDIO Y COMPRENSION DE LOS DATOS
Es importante realizar una comprensión de los datos disponibles en el data frame con el propósito de conocer a profundidad los casos de violaciones que se presentan en Colombia. Por lo tanto, a continuación se expondrán los datos más relevantes que fueron recolectados entre el 01 de enero del año 2010 al 31 de Mayo del año 2023.
Una vez abordado las características principales del dataset, se procede a examinar y abordar el problema de la violación en Colombia para prevenir y disminuir la violencia sexual en todas sus formas.
Se importan las bibliotecas pandas y numpy para el análisis de datos, panel para crear aplicaciones interactivas, y otras librerías como seaborn, matplotlib, y reportlab para visualización y generación de informes, además de unidecode para el procesamiento de texto.
Se importa el dataset a trabajar al entorno de trabajo Python.
FASE 3: PREPARACIÓN DEL DATASET
Ya cargado el dataset, se procede a realizar un análisis exploratorio y junto a ello la limpieza de datos (valores) para garantizar que los datos estén limpios y listos para el análisis. Comienza con la recolección de datos , seguida de la exploración inicial para identificar problemas como valores faltantes o atípicos. Luego, se realizan acciones de limpieza, como la imputación de valores nulos y la eliminación de duplicados, seguidas de la selección de características relevantes y la transformación de datos si es necesario.
Este código verifica la cantidad de valores nulos (NaN) y valores vacíos en cada columna del DataFrame "df" y luego imprime los resultados por separado. La variable "valores_nulos_por_columna" almacena la suma de valores nulos en cada columna, mientras que "valores_vacios_por_columna" almacena la cantidad de valores vacíos (representados como cadenas vacías) en cada columna del DataFrame. Las cantidades se imprimen en dos secciones separadas para una inspección rápida de la calidad de los datos.
Este código primero verifica si la carpeta 'data' existe; de lo contrario, la crea. Luego, itera a través de las columnas del DataFrame "df" y genera un archivo PDF separado para cada columna. Estos archivos contienen una lista de valores únicos en esa columna. Se utiliza ReportLab para crear los PDF, y los nombres de archivo se basan en el nombre de la columna. Finalmente, se imprime un mensaje que informa que los valores únicos en cada columna se han guardado como archivos PDF en la carpeta 'data'.
Este código normaliza y limpia un DataFrame llamado "df" al aplicar la función unidecode, convertir a minúsculas, estandarizar los nombres de las columnas, eliminar texto no deseado en la columna 'municipio', y reemplazar guiones en ciertas columnas por 'no reportado', mejorando así la consistencia y legibilidad de los datos.
Este código utiliza str.split para dividir la columna 'delito' en función de un punto y conservar solo la primera parte de cada entrada, lo que resulta en una simplificación de las descripciones de delitos en el DataFrame.
Este código filtra el DataFrame "df" para seleccionar todas las filas donde el valor en la columna 'departamento' sea igual a "cesar". El resultado será un nuevo DataFrame que contiene solo las filas correspondientes al departamento de Cesar.
Este código renombra las columnas 'armas_medio' a 'tipo_de_arma' y 'fecha_hecho' a 'fecha' en el DataFrame "df". El uso de inplace=True aplica los cambios directamente al DataFrame, y el resultado muestra las columnas renombradas.
Este código utiliza str.replace para eliminar "/ cortopunzante" de los valores en la columna 'tipo_de_arma' en el DataFrame "df". Después de aplicar esta operación, los valores en esa columna no contendrán la cadena "/ cortopunzante".
Este código utiliza el método str.split() para dividir la columna "fecha" en tres columnas separadas: 'dia', 'mes' y 'year'. Los valores de la columna "fecha" que estaban en el formato "dd/mm/yyyy" se dividen en estas tres nuevas columnas, lo que permite un acceso más fácil a los componentes individuales de la fecha. El resultado muestra el DataFrame con las columnas adicionales.
Este código crea una carpeta llamada 'data_procesada' si aún no existe. Luego, itera a través de las columnas del DataFrame "df" y genera archivos PDF separados para cada columna. Estos archivos contienen una lista de valores únicos en esa columna específica. Se utiliza la biblioteca ReportLab para crear los PDF, y los nombres de archivo se basan en el nombre de la columna. Finalmente, se imprime un mensaje que informa que los valores únicos en cada columna se han guardado como archivos PDF en la carpeta 'data_procesada'.
FASE 4: MODELADO
En esta fase del proyecto enfocado en las violaciones en Colombia, se procede a la creación y desarrollo de modelos que ayuden a comprender y predecir mejor los patrones de violencia sexual. Se aplican técnicas de análisis estadístico para identificar relaciones y tendencias en los datos recopilados. Esto incluye la exploración de factores demográficos, geográficos y temporales que puedan estar relacionados con las violaciones. Durante esta fase, se ajustan y validan los modelos para asegurarse de que sean precisos y útiles en la toma de decisiones.
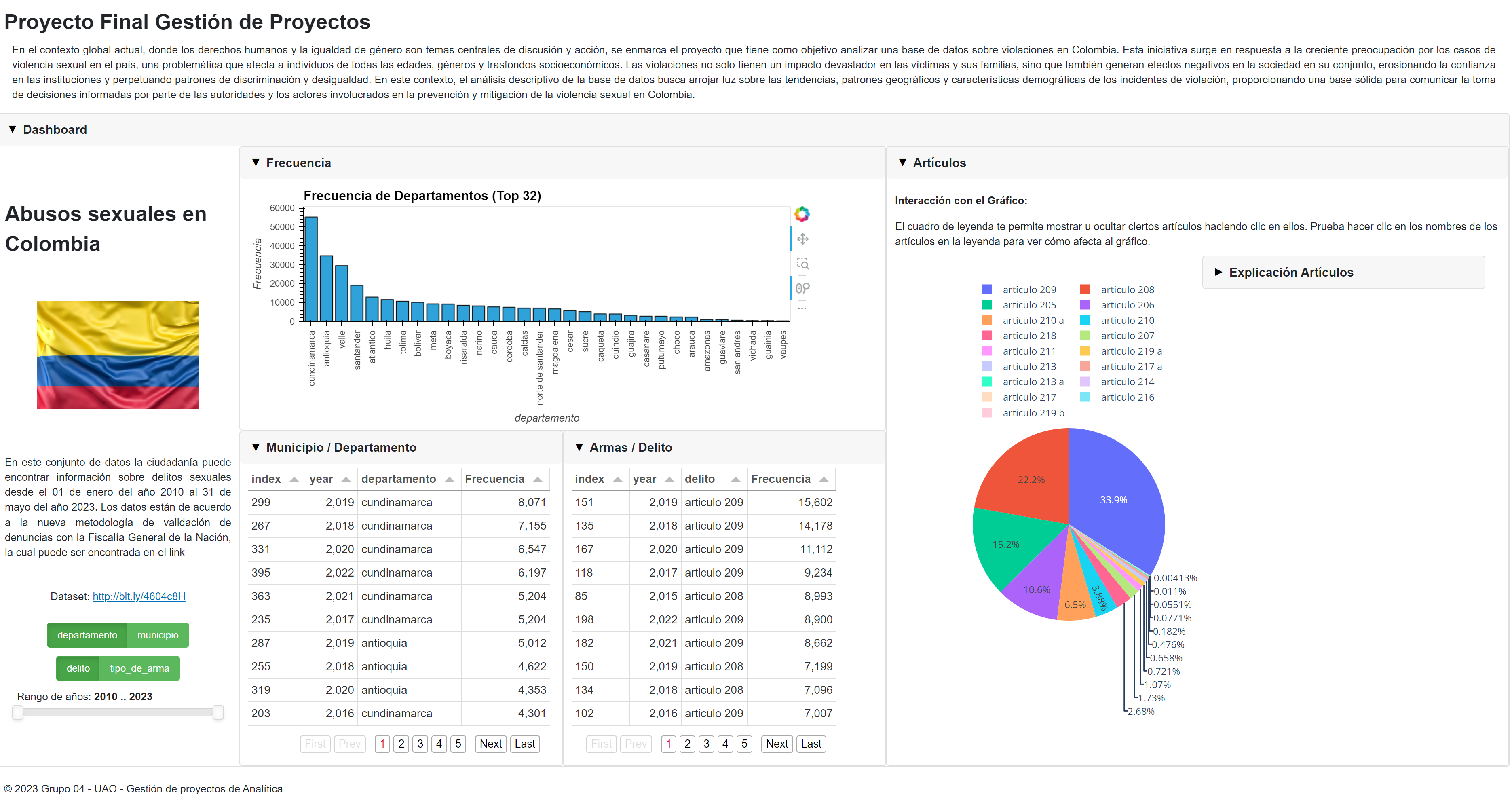
Este código calcula la frecuencia de cada valor en la columna 'departamento' del DataFrame "df". Luego, crea un gráfico de barras utilizando Seaborn para visualizar la frecuencia de cada departamento. El gráfico muestra los departamentos en el eje x y la frecuencia en el eje y. Además, se añade una tabla de leyenda que detalla la frecuencia de cada departamento debajo del gráfico. Se ajusta el tamaño del gráfico y se estiliza la tabla de leyenda para una mejor presentación. El resultado es un gráfico de barras con información detallada sobre la frecuencia de departamentos.
Este código filtra y crea un gráfico de pastel para mostrar la distribución de tipos de armas, excluyendo aquellos con un porcentaje del 0%. Los tipos de armas se etiquetan con sus porcentajes y se añaden números tanto en el gráfico como en la leyenda para una representación visual detallada de los datos.
Este código selecciona un conjunto de columnas en el DataFrame "df" llamadas 'codigo_dane', 'cantidad', 'year', 'dia', y 'mes'. Luego, aplica la función pd.to_numeric a estas columnas con el parámetro errors='coerce', lo que intenta convertir los valores a tipos numéricos y asigna NaN (no un número) en caso de que no sea posible realizar la conversión. Finalmente, llama a df.info() para mostrar información sobre el DataFrame actualizado, incluyendo los tipos de datos de las columnas. Esta operación puede ser útil para asegurarse de que las columnas seleccionadas contengan datos numéricos en lugar de objetos de texto.
En este fragmento de código, se define el nombre del archivo de salida como "datos_limpios.csv". Luego, se obtienen los tipos de datos de las columnas del DataFrame "df" y se almacenan en la variable "tipos_de_dato". Por último, el DataFrame se guarda en un archivo CSV utilizando el nombre de archivo especificado ("datos_limpios.csv") y la opción "index=False" para evitar que se incluyan los índices en el archivo CSV resultante. Esto permite guardar los datos limpios en un archivo CSV para su posterior uso o análisis.
El código crea un DataFrame interactivo llamado "idf" utilizando la función "interactive()" en el DataFrame original "df". Un DataFrame interactivo es una característica proporcionada por la biblioteca Panel que permite la exploración interactiva de datos en un entorno de panel interactivo. La función "head()" se utiliza para mostrar las primeras filas del DataFrame interactivo "idf", lo que permite una exploración interactiva de los datos.
En este código, se define un widget de Panel llamado "year_slider". Este widget es un control deslizante de rango de enteros que permite a los usuarios seleccionar un rango de años. El widget tiene un nombre visible en la interfaz de usuario, que es 'Rango de años', un ancho de 250 unidades, un valor inicial que comienza en 2010 y termina en 2023, y un valor inicial preseleccionado que también es (2010, 2023). Este widget puede ser utilizado en una aplicación interactiva de Panel para permitir a los usuarios filtrar y explorar datos basados en el rango de años que seleccionen.
En este código, se crea un grupo de botones de selección de tipo de datos llamado "bt2". Este grupo de botones RadioButtonGroup es un widget de Panel que permite a los usuarios seleccionar una opción de entre las proporcionadas. En este caso, las opciones son 'delito' y 'tipo_de_arma'. Los botones tienen un estilo de color 'success', lo que significa que se mostrarán en verde. Este widget puede ser utilizado en una aplicación interactiva de Panel para permitir a los usuarios elegir entre estas dos opciones de datos.
En este código, se crea un grupo de botones de radio llamado "radio_buttons" para permitir a los usuarios seleccionar entre dos opciones: 'departamento' y 'municipio'. Estos botones de radio están diseñados con un estilo de color 'success', lo que los hace ver en verde en la interfaz de usuario. Este widget puede ser utilizado en una aplicación interactiva de Panel para permitir a los usuarios alternar entre estas dos opciones de datos.
Este código define una función llamada "create_bar_chart" que crea una gráfica interactiva dependiendo de los valores seleccionados en los widgets "year_slider" y "radio_buttons". Primero, filtra el DataFrame según el rango de años seleccionado. Luego, calcula la frecuencia de departamentos o municipios en función de la selección del usuario y crea un gráfico de barras que muestra las 32 principales categorías. Finalmente, se crea un panel que incluye los widgets de selección y la gráfica interactiva, lo que permite a los usuarios explorar y visualizar datos de frecuencia de departamentos o municipios en función del rango de años seleccionado y el tipo de datos elegido.
El código define una función "create_table" que crea una tabla paginada basada en las selecciones de los widgets "year_slider" y "radio_buttons". Los datos se filtran, agrupan y ordenan según las preferencias del usuario. El panel resultante incluye widgets de selección de año y tipo de datos junto con la tabla paginada para explorar y visualizar los datos de frecuencia de departamentos o municipios según el rango de años y el tipo de datos seleccionado.
Este código define la función "create_table2" que crea una tabla paginada en función de las selecciones de los widgets "year_slider" y "bt2" (botones de selección de tipo de datos). Los datos se filtran, agrupan y ordenan según las preferencias del usuario. El panel final incluye widgets de selección de año y tipo de datos junto con la tabla paginada para explorar y visualizar datos de frecuencia de delitos o tipos de armas según el rango de años y el tipo de datos seleccionado.
Este código comienza calculando la frecuencia de los diferentes delitos en una columna llamada 'delito' y crea un nuevo DataFrame ordenado por frecuencia. Luego, utiliza Plotly Express para generar un gráfico de pastel interactivo que muestra la distribución de estos delitos en forma de porcentaje. También incluye una explicación sobre cómo interactuar con el gráfico y una lista detallada de los diferentes delitos. En conjunto, este panel interactivo permite a los usuarios explorar y comprender la frecuencia de los delitos de manera visual y detallada.
Este código crea un panel de control centrado que proporciona información sobre abusos sexuales en Colombia. Incluye un título, un logo de bandera, detalles sobre el conjunto de datos y enlaces a la fuente de los datos. Además, ofrece botones para seleccionar el tipo de datos a visualizar, un deslizador para elegir un rango de años, un gráfico de barras interactivo que muestra la frecuencia de departamentos o municipios, y tablas paginadas para explorar datos tabulares. El panel de control proporciona una manera centralizada y organizada de interactuar y visualizar información relacionada con abusos sexuales en Colombia.
Este código crea un encabezado (header) y un pie de página (footer) para el proyecto "Proyecto Final Gestión de Proyectos". El encabezado incluye un título centrado y un texto descriptivo que introduce el propósito del proyecto, destacando la importancia de abordar la problemática de la violencia sexual en Colombia. El pie de página muestra el año de copyright y se coloca en la parte inferior del panel. Además, se integra todo en un panel de control que incluye tanto el encabezado como el pie de página, creando una presentación completa y organizada del proyecto que puede ser servida y visualizada de manera interactiva.