import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow import Variable
from tensorflow import constant
from tensorflow import keras
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
Fundamentals
1. Calculate the parameters
2. Determine the amount of hidden layers and nodes
3. Build the neural network
4. Use the network to predict
Components of a neural network
Nodes
Activation functions
Parameters
weights
Biases
Neural networks with KERAS
Prediction models
importing data
wages_df = pd.read_csv('hourly_wages.csv')
wages_df.head()
predictors = np.array(wages_df[['union', 'education_yrs', 'experience_yrs', 'age',
'female', 'marr', 'south', 'manufacturing', 'construction']])
predictors
target = np.array(wages_df[['wage_per_hour']])
model creation
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
# Set up the model: model
model = Sequential()
adding layers
# Add the first layer
model.add(Dense(50, activation = 'relu', input_shape = (n_cols,)))
# Add the second layer
model.add(Dense(32, activation = 'relu'))
# Add the output layer
model.add(Dense(1))
compile and fit the model
# Compile the model
model.compile(optimizer = 'adam', loss = 'mean_squared_error')
# Fit the model
model.fit(predictors, target)
# Verify that model contains information from compiling
print("Loss function: " + model.loss)
Using the model to predict
model.predict([[ 0, 8, 21, 35, 1, 1, 0, 1, 0]])
Classification models
importing data
titanic_df = pd.read_csv('titanic_all_numeric.csv')
# The column is originally boolean, so we transform it
titanic_df['age_was_missing'] = titanic_df['age_was_missing'].astype(int)
titanic_df.head()
predictors = np.array(titanic_df[['pclass', 'age', 'sibsp', 'parch', 'fare', 'male',
'age_was_missing', 'embarked_from_cherbourg',
'embarked_from_queenstown', 'embarked_from_southampton']], dtype=float)
predictors
target = to_categorical(titanic_df[['survived']])
Creating the model
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
# Set up the model
model = Sequential()
# Add the first layer
model.add(Dense(32, activation = 'relu', input_shape = (n_cols,)))
# Add the output layer
model.add(Dense(2, activation = 'softmax'))
compile and fit the model
# Compile the model
model.compile(optimizer = 'sgd', loss = 'categorical_crossentropy', metrics = ['accuracy'])
# Fit the model
model.fit(predictors, target)
using the model to predict
model.predict([[ 3, 22, 1, 0, 7.25, 1, 0, 0, 0, 1]])
Model optimization
def get_new_model(input_shape = n_cols):
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = (input_shape,)))
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
return(model)
lr_to_test = [.000001, 0.01, 1]
# Loop over learning rates
for lr in lr_to_test:
print('\n\nTesting model with learning rate: %f\n'%lr )
# Build new model to test, unaffected by previous models
model = get_new_model()
# Create SGD optimizer with specified learning rate: my_optimizer
my_optimizer = SGD(lr = lr)
# Compile the model
model.compile(optimizer = my_optimizer, loss = 'categorical_crossentropy')
# Fit the model
model.fit(predictors, target)
Classification models: Binary classification
importing data
banknotes = pd.read_csv('banknotes.csv')
banknotes.head()
Describing the dataset
# Use pairplot and set the hue to be our class column
sns.pairplot(banknotes, hue='class')
# Show the plot
plt.show()
# Describe the data
print('Dataset stats: \n', banknotes.describe())
# Count the number of observations per class
print('Observations per class: \n', banknotes['class'].value_counts())
Normalize the dataset
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
banknotes_standardized = pd.DataFrame(
scaler.fit_transform(banknotes[['variace', 'skewness', 'curtosis', 'entropy']]),
columns=['variace', 'skewness', 'curtosis', 'entropy']
)
Creating the model
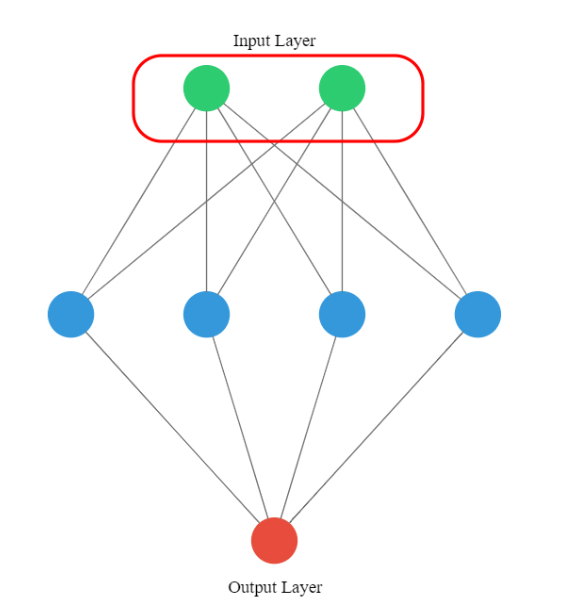
# Create a sequential model
model = Sequential()
# Add a dense layer
model.add(Dense(1, input_shape=(4,), activation='sigmoid'))
# Compile your model
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
# Display a summary of your model
model.summary()
Split into training and testing data
# Split the dataset into features (X) and labels (y)
X = banknotes_standardized
y = banknotes['class']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Training the model
# Train your model for 20 epochs
model.fit(X_train, y_train, epochs = 20)
# Evaluate your model accuracy on the test set
accuracy = model.evaluate(X_test, y_test)[1]
# Print accuracy
print('Accuracy:', accuracy)
Classification models: Multiclass classification
darts = pd.read_csv('darts.csv')
darts.head()
describing the dataset
sns.pairplot(darts, hue = 'competitor')
plt.show()
# Transform into a categorical variable
darts.competitor = pd.Categorical(darts.competitor)
# Assign a number to each category (label encoding)
darts.competitor = darts.competitor.cat.codes
# Import to_categorical from keras utils module
from tensorflow.keras.utils import to_categorical
coordinates = darts.drop(['competitor'], axis=1)
# Use to_categorical on your labels
competitors = to_categorical(darts.competitor)
# Now print the one-hot encoded labels
print('One-hot encoded competitors: \n',competitors)
Split into training and testing data
# Split the dataset into features (X) and labels (y)
X = darts[['xCoord', 'yCoord']]
y = competitors
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Creating the model
# Instantiate a sequential model
model = Sequential()
# Add 3 dense layers of 128, 64 and 32 neurons each
model.add(Dense(128, input_shape=(2,), activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
# Add a dense layer with as many neurons as competitors
model.add(Dense(4, activation='softmax'))
# Compile your model using categorical_crossentropy loss
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Training the model
# Fit your model to the training data for 200 epochs
model.fit(X_train,y_train,epochs=200)
# Evaluate your model accuracy on the test data
accuracy = model.evaluate(X_test, y_test)[1]
# Print accuracy
print('Accuracy:', accuracy)
evaluating predictions
coords_small_test = darts[['xCoord', 'yCoord']].sample(n=5)
# Predict on coords_small_test
preds = model.predict(coords_small_test)
pd.DataFrame(preds*100)
final accuracy
# Predict on coords_small_test
preds = model.predict(X_test)
predicted_categories = np.argmax(preds, axis=1)
real_categories = np.argmax(y_test, axis = 1)
final_accuracy = ((predicted_categories == real_categories).sum())/len(y_test)
final_accuracy
Classification models: MultiLabel classification
describing the dataset
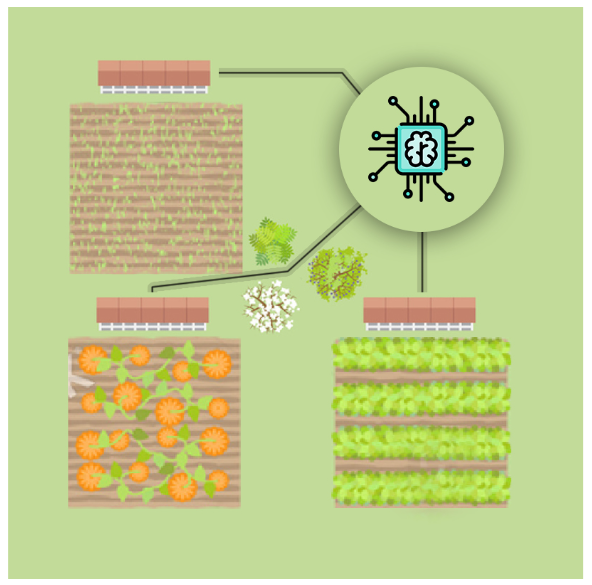
#reading the dataframe and deleting a column that only contains indexes
parcels_df = pd.read_csv('irrigation_machine.csv').drop('Unnamed: 0', axis = 1)
parcels_df
Architecture Description
Split into training and testing data
# Split the dataset into features (X) and labels (y)
X = parcels_df.drop(['parcel_0', 'parcel_1', 'parcel_2'], axis = 1)
y = parcels_df[['parcel_0', 'parcel_1', 'parcel_2']]
# Split into training and testing sets
sensors_train, sensors_test, parcels_train, parcels_test = train_test_split(X, y, test_size=0.3, random_state=42)
Creating the model
# Instantiate a Sequential model
model = Sequential()
# Add a hidden layer of 64 neurons and a 20 neuron's input
model.add(Dense(64, activation='relu',input_shape=(20,)))
# Add an output layer of 3 neurons with sigmoid activation
model.add(Dense(3, activation = 'sigmoid'))
# Compile your model with binary crossentropy loss
model.compile(optimizer='adam',
loss = 'binary_crossentropy',
metrics=['accuracy'])
model.summary()
Training the model
# Train for 100 epochs using a validation split of 0.2
model.fit(sensors_train, parcels_train, epochs = 100, validation_split = 0.2)
# Predict on sensors_test and round up the predictions
preds = model.predict(sensors_test)
preds_rounded = np.round(preds)
# Print rounded preds
print('Rounded Predictions: \n', preds_rounded)
# Evaluate your model's accuracy on the test data
accuracy = model.evaluate(sensors_test, parcels_test)[1]
# Print accuracy
print('Accuracy:', accuracy)
Making predictions
parcels_small_test = parcels_df.drop(['parcel_0', 'parcel_1', 'parcel_2'], axis=1).sample(n=5)
# Predict on coords_small_test
preds = model.predict(parcels_small_test)
pd.DataFrame(preds*100)
Keras History Callback
# ------------------ Importing the data ----------------------------
parcels_df = pd.read_csv('irrigation_machine.csv').drop('Unnamed: 0', axis = 1)
# ------------------ Split into training and testing sets ----------------------
X = parcels_df.drop(['parcel_0', 'parcel_1', 'parcel_2'], axis = 1)
y = parcels_df[['parcel_0', 'parcel_1', 'parcel_2']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# ------------------- Create the model ---------------------------
# Instantiate a Sequential model
model = Sequential()
# Add a hidden layer of 64 neurons and a 20 neuron's input
model.add(Dense(64, activation='relu',input_shape=(20,)))
# Add an output layer of 3 neurons with sigmoid activation
model.add(Dense(3, activation = 'sigmoid'))
# Compile your model with binary crossentropy loss
model.compile(optimizer='adam',
loss = 'binary_crossentropy',
metrics=['accuracy'])
# Train your model and save its history
h_callback = model.fit(X_train, y_train, epochs = 25,
validation_data=(X_test, y_test))
Plot train vs test loss during training
def plot_loss(loss,val_loss):
plt.figure()
plt.plot(loss)
plt.plot(val_loss)
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()
plot_loss(h_callback.history['loss'], h_callback.history['val_loss'])
Plot train vs test accuracy during training
def plot_accuracy(acc,val_acc):
# Plot training & validation accuracy values
plt.figure()
plt.plot(acc)
plt.plot(val_acc)
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
plot_accuracy(h_callback.history['accuracy'], h_callback.history['val_accuracy'])
Early Stopping a model training
# ---------------------- Importing data ----------------------------
banknotes = pd.read_csv('banknotes.csv')
# ---------------------- Scaling the data --------------------------
scaler = StandardScaler()
banknotes_standardized = pd.DataFrame(
scaler.fit_transform(banknotes[['variace', 'skewness', 'curtosis', 'entropy']]),
columns=['variace', 'skewness', 'curtosis', 'entropy']
)
# ---------------- Split into training and testing sets -------------
# Split the dataset into features (X) and labels (y)
X = banknotes_standardized
y = banknotes['class']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create a sequential model
model = Sequential()
# Add a dense layer
model.add(Dense(1, input_shape=(4,), activation='sigmoid'))
# Compile your model
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
# Define a callback to monitor val_accuracy
monitor_val_acc = EarlyStopping(monitor='val_accuracy',
patience=5)
# Train your model using the early stopping callback
model.fit(X_train, y_train,
epochs=1000, validation_data=(X_test, y_test),
callbacks= [monitor_val_acc])
Model Checkpoint
# ---------------------- Importing data ----------------------------
banknotes = pd.read_csv('banknotes.csv')
# ---------------------- Scaling the data --------------------------
scaler = StandardScaler()
banknotes_standardized = pd.DataFrame(
scaler.fit_transform(banknotes[['variace', 'skewness', 'curtosis', 'entropy']]),
columns=['variace', 'skewness', 'curtosis', 'entropy']
)
# ---------------- Split into training and testing sets -------------
# Split the dataset into features (X) and labels (y)
X = banknotes_standardized
y = banknotes['class']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create a sequential model
model = Sequential()
# Add a dense layer
model.add(Dense(1, input_shape=(4,), activation='sigmoid'))
# Compile your model
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
# Early stop on validation accuracy
monitor_val_acc = EarlyStopping(monitor = 'val_accuracy', patience = 3)
# Save the best model as best_banknote_model.hdf5
model_checkpoint = ModelCheckpoint('best_banknote_model.hdf5', save_best_only = True)
# Fit your model for a stupid amount of epochs
h_callback = model.fit(X_train, y_train,
epochs = 1000000000000,
callbacks = [monitor_val_acc, model_checkpoint],
validation_data = (X_test, y_test))
Tensorflow
What is a tensor?
#0D Tensor
d0 = tf.ones((1,))
d0
# 1D Tensor
d1 = tf.ones((2,))
# 2D Tensor
d2 = tf.ones((2, 2))
# 3D Tensor
d3 = tf.ones((2, 2, 2))
d0.numpy()
d2.numpy()
Constants
# Define a 2x3 constant.
a = constant(3, shape=[2, 3])
a
# Define a 2x2 constant.
b = constant([1, 2, 3, 4], shape=[2, 2])
b
Variables
# Define the 1-dimensional variable A1
A1 = Variable([1, 2, 3, 4])
# Print the variable A1
print('\n A1: ', A1)
# Convert A1 to a numpy array and assign it to B1
B1 = A1.numpy()
# Print B1
print('\n B1: ', B1)
Operations
addition
# Define 2-dimensional tensors
A2 = tf.constant([
[1, 2],
[3, 4]
])
B2 = tf.constant([
[5, 6], [7, 8]
])
C2 = tf.add(A2, B2)
C2
element wise multiplication
# Define tensors
A0 = tf.ones(1)
# The parameters here are dimensions of the array
A31 = tf.ones([3, 1])
A34 = tf.ones([3, 4])
A43 = tf.ones([4, 3])
tf.multiply(A34, A34)
Matrix multiplication (dot product)
A34 = tf.ones([3, 4])
A43 = tf.ones([4, 3])
print(A43)
print(A34)
print(tf.matmul(A43, A34 ))
tf.random.uniform([2, 2, 3], maxval=255, dtype='int32').numpy()