Deep learning: Tp noté
Membre du groupe: Nicolas Bitaillou, Mathis Emeriau , Marius Guitton-Frantz
Explication
Question 1
Algorithme choisit:
Durant ce tp noté, nous allons utilisé un algorithme de "Convolution neural network (CNN)". Le réseau de neurones convolutifs, ou CNN pour faire court, est un type spécialisé de modèle de réseau de neurones conçu pour travailler avec des données d'images bidimensionnelles, bien qu'ils puissent être utilisés avec des données unidimensionnelles et tridimensionnelles.
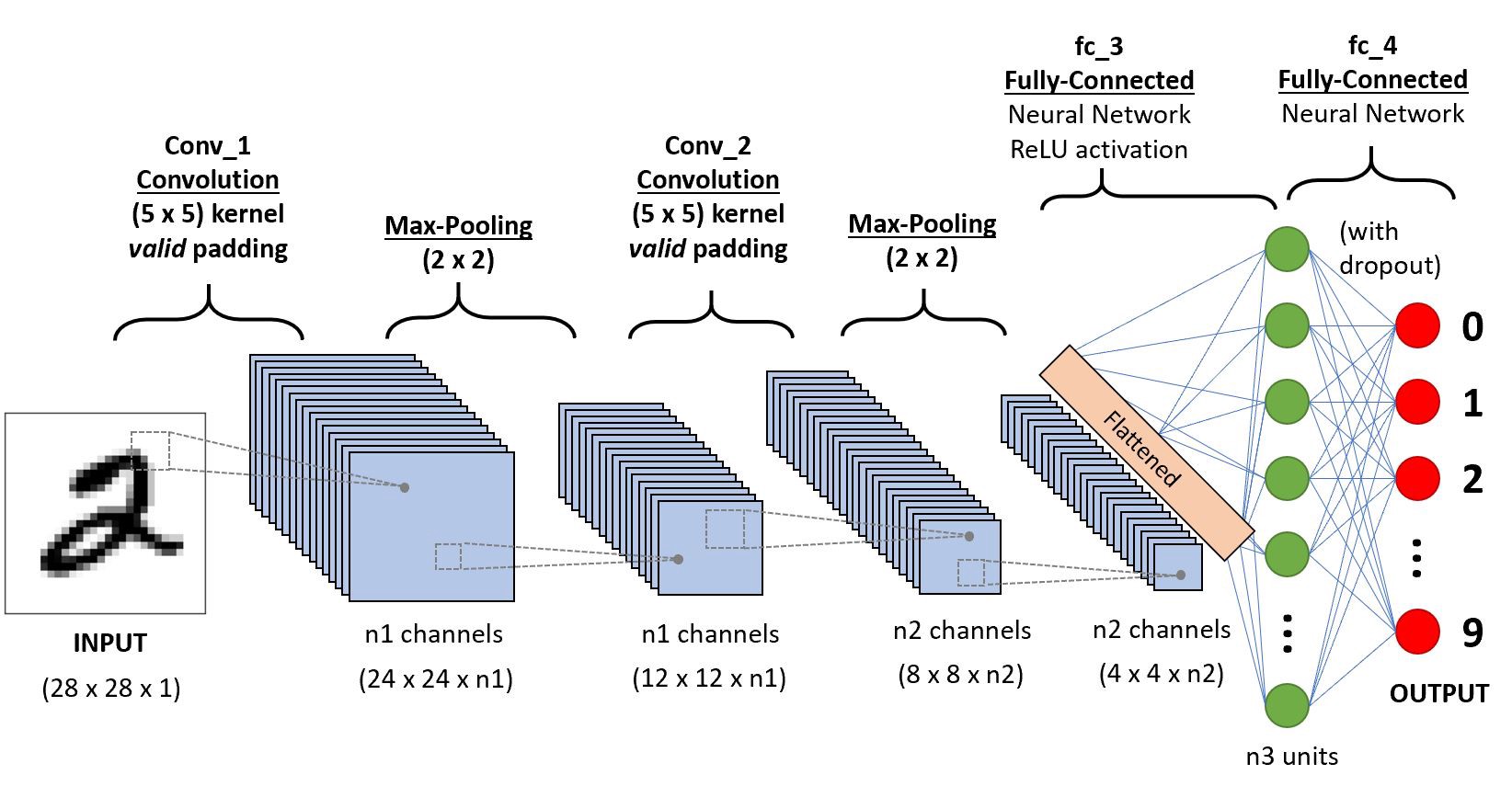
Concepts spécifiques à l’apprentissage profond:
Fonction d'activation :
Dans un réseau de neurones, la fonction d'activation est utilisée pour introduire de la non-linéarité. Elle détermine si une cellule (ou neurone) doit être activée ou non en fonction de sa valeur d'entrée. La fonction d'activation fréquemment utilisé avec CNN est la fonction ReLU (Rectified Linear Unit), qui est définie comme f(x) = max(0, x). Elle remplace les valeurs négatives par zéro, laissant passer les valeurs positives.
Convolution :
La convolution est le processus fondamental des CNN. Elle consiste à appliquer un filtre sur une partie de l'image d'entrée pour extraire des caractéristiques locales. En déplaçant ce filtre sur l'ensemble de l'image, on obtient une carte de caractéristiques qui met en évidence les motifs importants de l'image, tels que les bords, les textures, etc.

Pooling :
Le pooling, également appelé échantillonnage, est une opération qui réduit la taille spatiale des cartes de caractéristiques. Le pooling le plus courant est le max-pooling, qui consiste à prendre la valeur maximale d'une région donnée de la carte de caractéristiques. Le pooling permet de réduire la dimension de l'entrée, ce qui réduit le nombre de paramètres et améliore l'invariance aux translations.
Sequential Neural Network (Réseau neuronal séquentiel) :
Un Sequential Neural Network est un type de modèle de réseau de neurones profonds où les couches sont empilées de manière séquentielle. Chaque couche prend les sorties de la couche précédente en entrée. Les CNN sont souvent mis en œuvre en tant que réseaux séquentiels, avec des couches de convolution, de pooling et de couches entièrement connectées.
Couche de neurones :
Une couche de neurones est un ensemble de neurones qui effectuent des opérations sur les données d'entrée. Chaque couche extrait des informations spécifiques de l'image ou des caractéristiques, et ces informations sont progressivement affinées à mesure que l'on avance dans le réseau.
Backpropagation :
La rétropropagation (backpropagation) est l'algorithme utilisé pour entraîner un réseau de neurones. Il calcule les gradients des poids du réseau par rapport à une fonction de perte, puis ajuste ces poids pour minimiser la perte. Dans notre cas, la rétropropagation est utilisée pour ajuster les filtres, les poids des connexions entre les neurones, et les biais afin d'améliorer la capacité du réseau à effectuer des tâches spécifiques, comme la classification d'images.
Les CNN sont particulièrement adaptés aux traitement d'images en raison de leur capacité à apprendre des représentations hiérarchiques à partir des données. En combinant la convolution, le pooling, les fonctions d'activation et la rétropropagation, les CNN sont capables d'extraire des caractéristiques importantes des images, ce qui les rend largement utilisés dans des applications telles que la reconnaissance d'objets, la détection de visages et bien d'autres.
Explication détaillée de l'algorithme
L'algorithme commence par répartir les données en dataset d'entraînement et de test. Il ne faut pas que le découpage ait une mauvaise proportion sinon cela pourrait mener à de l'overfitting (le réseau sera trop spécialisé sur ces données en particulier et n'arrivera pas à généraliser dans le futur). D'ailleurs, ici on a un découpage de 1/6 ce qui correspond à environ 17%. En général, on tourne plutôt autour de 20% pour éviter au mieux l'overfitting.
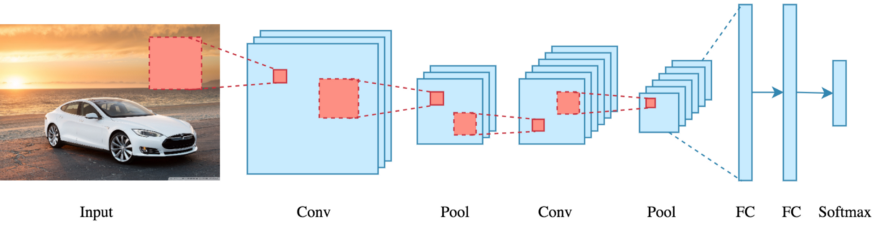
L'algorithme choisit utilise 7 couches de neurones agencées selon cette forme : Conv2D --> Pooling Layer --> Conv2D --> Pooling layer --> Flatten Layer (Redimensionne les données multi-dimensionelles en entrée vers des données vectorielles à une seul dimension, car le pooling layer à en sortie des données multi dimensionnelles et le layer Dense prend une donnée en 1 seule dimension en entrée) --> Dense Layer (Relu) --> Dense Layer (Softmax)
Explication des résultats obtenus
Les métriques de "Loss" (perte) et d'"Accuracy" (exactitude) sont des métriques couramment utilisées pour évaluer les performances des modèles d'apprentissage automatique.
La perte est une mesure de l'erreur du modèle. Elle évalue à quel point les prédictions du modèle diffèrent des valeurs réelles dans l'ensemble de données d'entraînement. L'objectif principal lors de l'entraînement d'un modèle est de minimiser la perte. Plus la perte est faible, meilleure est la performance du modèle.
L'exactitude est une mesure de la performance d'un modèle dans une tâche de classification. Elle indique la proportion de prédictions correctes parmi l'ensemble des échantillons. Plus l'exactitude est élevée, meilleure est la capacité du modèle à classer correctement les données. Cependant avoir une exactitude trop élevé est parfois le signe d'un overfitting.
Résultat
On obtient les résultats suivant: loss: 2.0503 - accuracy: 0.6614
Avec le modèle, on peut générer un graphe des valeurs en fonction des epochs.
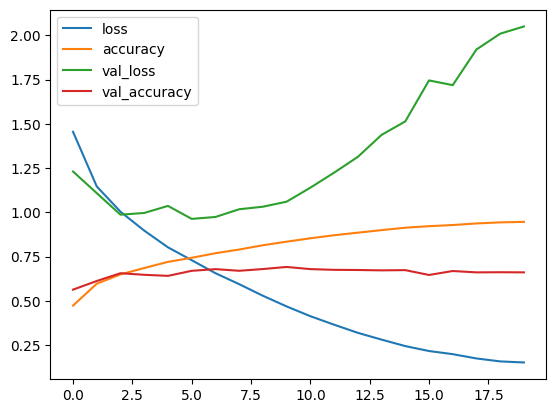
Les résultats obtenus par ce premier modèle sont pas forcément mauvaise mais elle peuvent être amélioré. Pour que l'exactitude ou accuracy soit acceptable il faut que la valeur soit comprise entre 80% et 90%, ce qui n'est pas notre cas. Pour le cas de la valeur perte ou loss on observe une valeur de de 2.0503 ce qui est plutôt médiocre quand on considère que la valeur doit éviter de dépasser 0.5 pour être considéré acceptable.