Conociendo nuestros datos de pingüinos. 🗺🧭🐧
Instalar librerías necesarias
Importar librerías
Run to view results
Establecer apariencia general de los gráficos
Run to view results
Cargar los datos
Utilizando el paquete palmerpenguins
Datos crudos
Run to view results
Datos previamente procesados
Run to view results
Utilizando los conjuntos de datos de seaborn
Run to view results
Utilizando la interfaz de Deepnote
Links de importación de datos:
Run to view results
Run to view results
hasta acá se importó el dataframe
Colecta y validación de datos
¿Qué tipo de dato son las variables del conjunto de datos?
Run to view results
¿Cuántas variables de cada tipo de dato tenemos en el conjunto de datos?
Run to view results
¿Cuántas variables y observaciones tenemos en el conjunto de datos?
Run to view results
¿Existen valores nulos explicitos en el conjunto de datos?
Run to view results
De tener observaciones con valores nulos, ¿cuántas tenemos por cada variable?
Run to view results
¿Cuántos valores nulos tenemos en total en el conjunto de datos?
Run to view results
¿Cuál es la proporción de valores nulos por cada variable?
Run to view results
Run to view results
¿Cómo podemos visualizar los valores nulos en todo el conjunto de datos?
Run to view results
¿Cuántas observaciones perdemos si eliminamos los datos faltantes?
Run to view results
Conteos y proporciones
Preludio: ¿Qué estadísticos describen el conjunto de datos?
Todas las variables
Run to view results
Solo las numéricas
Run to view results
Solo categóricas - 1
Run to view results
Solo categóricas - 2
Run to view results
¿Cómo visualizar los conteos?
Pandas
Run to view results
Seaborn
Run to view results
Run to view results
¿Cómo visualizar las proporciones?
Run to view results
Medidas de tendencia central
Media o promedio
Run to view results
Run to view results
Run to view results
Mediana
Run to view results
Moda
Run to view results
Run to view results
Estadistica Descriptiva Aplicada
Promedio de una variable usando pandas
data_frame.variable.mean()
Promedio de una variable usando numpy
np.mean(data_frame.variable)
Promedio para todas las variables numericas de un df
data_frame.mean()
Si al utilizar la funcion mean() sobre todo el dataset python les eleva una advertencia, esto puedo deberse a que hay columnas que no son numericas, para evitar esta advertencia prueba con: data_frame.mean( numeric_only= 'True' )
Mediana para todas las variables numericas del df
data_frame.median()
La moda se puede obtener para las variables tanto categoricas como numericas del df
data_frame.mode()
Información estadísticas de las variables categóricas
preprocessed_penguins_df.describe(include='object')
Medidas de dispersión
q tan cerca o tan lejos estas tus datos en relacion a estas medidas de tendencia central (moda, mediana, media)? para eso eso usamos las medidas de dispersión: rango, rango intercuatilico, desviación estandar.
Una curtosis mayor a 0 indica que la mayoria de los datos estan muy concentrados alrededor de la media, lo cual indica que hay poca variabilidad en los datos, es decir, el rango es pequeño. Una curtosis negativa indica lo contrario, los datos estan alejados de la media, lo cual indica mucha variabilidad en los datos, su rango es amplio
¿Cuál es el valor máximo de las variables?
Para conocer el rango tengo que saber los valores máximos y mínimos
Run to view results
Run to view results
¿Cuál es el valor mínimo de las variables?
Run to view results
¿Cuál es el rango de las variables?
Run to view results
¿Cuál es la desviación estándar de las variables?
Run to view results
si a la media le sumo la desviación estandar (std) y a la media le resto std. ese rango entre los dos resultados me va a dar el 65% de los datos (en distribución normal)
¿Cuál es el rango intercuartílico?
la media s epuede alterar con los valores atípicos. En cambio con los rangos intercuartiles son muy robustos porque se basan en percentiles (partimos nuestros datos en partes iguales, entonces nos evitamos estos sesgos si tneemos valores atipiocs
Run to view results
Run to view results
Run to view results
¿Cómo puedo visualizar la distribución de una variable?
Histograma
vamos a ver el diagrama de frecuncia de nuestros datos
Run to view results
Diagrama de caja / boxplot
Otra forma d evisualizar estos estadísticos de una forma muy sencilla es con un boxplot
Run to view results
Run to view results
Limitaciones
Run to view results
Run to view results
Distribuciones: PMFs, CDFs y PDFs
Funciones de probabilidad de masas (PMFs)
Utilizando seaborn
Run to view results
Utilizando empiricaldist
Run to view results
Run to view results
Run to view results
Run to view results
Funciones empirícas de probabilidad acumulada (ECDFs)
Utilizando seaborn
Run to view results
Utilizando empiricaldist
Run to view results
Run to view results
Run to view results
Comparando distribuciones
Run to view results
Funciones de densidad de probabilidad
Run to view results
Run to view results
Run to view results
Run to view results
Ley de los Grandes Números y Teorema del Límite Central
Ley de los Grandes Números
Run to view results
Run to view results
Teorema del límite central
Run to view results
Run to view results
Run to view results
Run to view results
Run to view results
Run to view results
La media de las muetras tiende aproximadamente a una distribución normal. Al ir calculando y aumentando el tamaño de las muestras vimos que podiamos calcular y encontrar la proporcion de machos en la poblacion sin problema, tomando pequeños muestreos cada vez y calculando los promedios.
Estableciendo relaciones: Gráfica de puntos
Run to view results
Run to view results
Run to view results
Run to view results
Estableciendo relaciones: Gráficos de violín y boxplots
vamos a relacionar variable categorica y una numerica
Run to view results
meterle ruido
Run to view results
boxplot para visualizar propiedades estadísitcas que tiene nuestro conjunto de datos para cada una de nuestras variables categóricas
Run to view results
Run to view results
Run to view results
Run to view results
Estableciendo relaciones: Matrices de correlación
Si desean profundizar sobre la definicion del coeficiente de correlacion, les recomiendo leer a partir de la pagina 147 de este libro (que fue uno de los libros guía para el curso): https://cims.nyu.edu/~cfgranda/pages/stuff/probability_stats_for_DS.pdf
¿Existe una correlación lineal entre alguna de nuestras variables?
Run to view results
¿Como puedo visualizar los coeficientes de correlación?
Run to view results
Año no está muy relacionado con las otras variables
Run to view results
¿Cómo podría representar una variable categórica como numérica discreta?
ver si variable categorica está relacionada con numerica
Run to view results
Run to view results
Coeficiente Pearson: como visualizarlo graficamente de manera efectiva para obtener insagt visuales para ayudarte a identificar si hay o no una correlación y que tan fuerte es
¿Cuál es una límitante de los coeficientes de correlación lineal?
Sólo nos ayuda a determinar la posible existencia de una correlación lineal, sin embargo, su ausencia no significa que no exista otro tipo de correlación
Run to view results
Run to view results
Run to view results
El coeficiente de correlación no nos habla del impacto de la relación. (Podemos tener coeficiente de correlacion mas alto que otro, pero no quiere decir que nos va a servir para predecir o par ahacer algo que no de impacto)
Run to view results
de correlacion no nos alcanza para ver la fuerza del efecto
Estableciendo relaciones: Análisis de regresión simple (para establecer la fuerza del efecto)
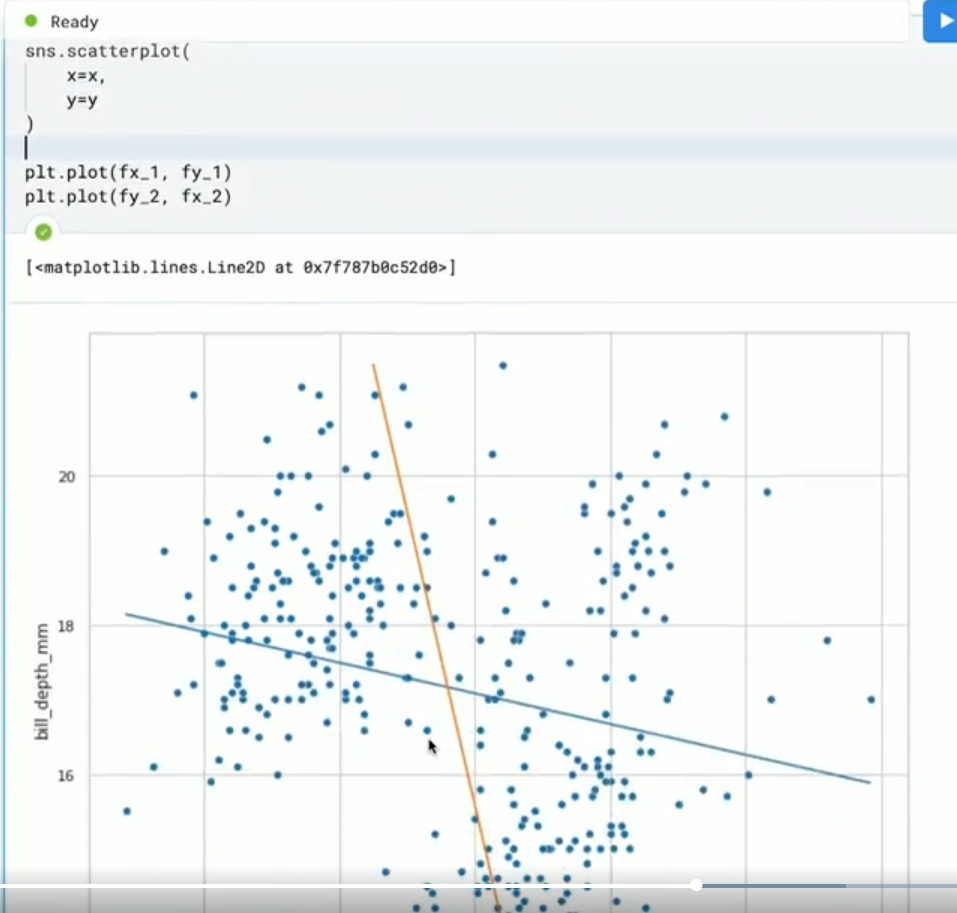
La regresión lineal es una técnica que nos ayuda a hacer comparaciones entre los puntos en el plano cartesiano. es decir, que para un valor de X existe un valor de Y, esto se empieza a graficar sobre el plano como un grafico de dispersión
para esos datos, hay que ajustar una linea recta que mejor los entienda, ósea el modelo trata de predecir el mejor ajuste para la linea recta en esos datos.
La función matemática correspondiente a este problema es Y=w0 + w1x
X es un valor que existe sobre el plano W0 es el punto que se esta cortando sobre el plano, es decir, cuando X = 0 cual es el salto que existe el punto de X = 0 y el plano en el eje Y. W1 es cuando se agrega un valor a la X cuanto salto sobre Y Básicamente esto se conoce como w0 el Intercepto y w1 la pendiente de la linea recta.
durante el ajuste del modelo de regresión lineal se conocen como los pesos del modelo, estos son los valores que va a estar intentando aprender el modelo para entender cual va a ser la mejor linea recta que se va a ajustar a los datos.
Run to view results
slope = efecto que tiene esta correlación en caso de q exista. 0.1 estamos esperando un cambio muy pequeño cuando el cambio de x (azules)
slope = 0.54 mayor impacto en el conjunto de datos que estaban mas dispersos (naranja)
p_value = para saber si la correlación lineal es significativa
Run to view results
Run to view results
Run to view results
Limitaciones del análisis de regresión simple
La regresión lineal simple no es simétrica
Run to view results
slope nos importa porque nos va a explicar como cambia una variable respecto a la otra
Run to view results
Run to view results
La regresión no nos dice nada sobre la causalidad, pero existen herramientas para separar las relaciones entre varias variables
La pendiente es -0.634905, lo que significa que cada milímetro adicional de profundidad del pico es asociado a un decremento de -0.634905 milímetros de la longitud del pico de un pingüino.
Run to view results
Run to view results
Limitacion del Analisis de Regresion Simple La regresion lineal simple de A - B no es lo mismo que B - A. Las regresiones pueden ser diferentes en cada caso. Debes elegir de correctamente cual sera la variable independiente y dependiente.
Si dos variables crecen o decrecen siguiendo las mismas pautas, no implica necesariamente que una cause la otra. Correlacion no implica causalidad.
Solo puede manejar relaciones lineales. Es importante visualizar los datos para poder determinar que tipo de regression utilizar.
Análisis de regresión múltiple
El análisis de regresión múltiple es una técnica estadística utilizada para modelar la relación entre una variable de respuesta o dependiente y dos o más variables predictoras o independientes. A diferencia del análisis de regresión simple, que utiliza solo una variable predictora, el análisis de regresión múltiple permite analizar cómo dos o más variables predictoras influyen en la variable de respuesta. El objetivo del análisis de regresión múltiple es crear un modelo matemático que describa la relación entre las variables independientes y la variable dependiente. El modelo se utiliza para predecir los valores de la variable de respuesta en función de los valores de las variables predictoras. Además, el análisis de regresión múltiple puede ayudar a identificar qué variables predictoras son significativas para predecir la variable de respuesta. En el análisis de regresión múltiple, la variable dependiente debe ser continua, mientras que las variables predictoras pueden ser continuas o categóricas. Se utilizan diferentes técnicas estadísticas para ajustar el modelo de regresión múltiple y estimar los coeficientes de las variables predictoras.
Olvidé mi báscula para pesar a los pingüinos, ¿Cuál sería la mejor forma de capturar ese dato?
Creando modelos
Run to view results
Run to view results
Run to view results
Run to view results
Run to view results
Visualizando resultados
Run to view results
Run to view results
Run to view results
Run to view results
Análisis de regresión logística
Run to view results
Run to view results
Run to view results
Run to view results
Run to view results
Run to view results
Run to view results
Run to view results
Jeinfferson Bernal G
Estudiante • hace 2 años Modelo para definir si un pinguino es Macho o Hembra
Creamos el modelo con las variables que consideremos influyen en la eleccion de si es un macho o hembra. Nuestra variable objetivo es categorica (sexo), por tanto, debemos convertirla en numerica para poder aplicar al modelo.
Run to view results
Dado que la variable sexo es categorica la convertimos en 0(hembras) y 1(machos), los resultados de la Regresion Logistica viene dado en funcion de los machos.
Los resultados se interpretan asi:
A mayor longitud de las aletas, mas probable que el pinguino sea macho (0.1393). A mayor longitud de los picos, mas probable que el pinguino sea macho (0.1413). Mientras mas ancho el pico, mas probable que sea macho (1.6401) Es menos probable que hayan machos en la isla Dream respecto a la Biscoe (-1.55) Es menos probable que hayan machos en la isla Torgensen respecto a la Biscoe (-1.03) El parametro P > abs(Z) indica cuales son las variables mas significativas estadisticamente para el resultado. Mientras mas tienda al valor 0 mas significativa es.
Cuando tenemos tres variables y en los resultados de la regresion logistica solo aparecen dos, indica que los esos valores son respecto a la variable faltante
Probabilidad de que hayan mas machos en la isla Dream que en la isla Torgensen
Run to view results
Respecto a la isla Dream, es mas probable encontrar macho en la isla Dream que en la Torgensen
Exploracion de las variables categoricas. Con un EDA inicial en las variables categoricas podriamos haber llegado a las misma conclusiones que el modelo logistico
#Tabla de conteo de las variables categoricas isla y sexo ( preprocessed_penguins_df .value_counts(['island', 'sex']) .reset_index(name='count') )
Paradoja de Simpson
Este video me ayudo a entender mejor la Paradoja de Simpson: https://www.youtube.com/watch?v=hpbXkrm68rI&ab_channel=MinutoDeFisica
Dejo más data por aquí: https://es.wikipedia.org/wiki/Paradoja_de_Simpson
Run to view results
Run to view results
Run to view results
Run to view results
Que hacer cuando tengo muchas variables? Cuando se tiene muchas variables, un analisis de pares de variables puede ser confuso por lo que tenemos que recurrir a tecnicas que nos ayudan a entender la variacion de todos los datos de manera simple: Reduciendo las dimensiones para obtener un unico espacio (Pasar de 10 variables a solo 2). Algunas de estas tecnicas son:
Analisis de Componentes Principales (PCA): un ejemplo de utilidad es la demostracion de que los genes reflejan la geografia de Europa TSNE (T - Distributed Stochastic Neighbor Embedding): Separacion de todos los tipos de cancer UMAP (Uniform Manifold Approximation and Projection for Dimension Reduction): intenta capturar la estructura global preservando la estructura local de los datos utlizando proyecciones en un plano Comparacion: algoritmo de reduccion de dimension vs conjunto de datos
Información de sesión
Run to view results