Metodo de Monte Carlo
Elaborado por: Guillermo Alvarez y Domenica Escobar
Introducción
El método Monte Carlo, que lleva el nombre del famoso Casino Monte Carlo de M�ónaco, es un método estadístico que se ha convertido en una herramienta fundamental en diversos campos, desde la física hasta la ingeniería y la economía. Sus aplicaciones se extienden a una variedad de problemas que involucran procesos estocásticos y generación de números aleatorios.
En este ejercicio práctico, nos sumergiremos en el fascinante mundo de la integración numérica de Monte Carlo, centrándonos específicamente en dos enfoques clave: el método de muestreo (sampling) y el método "Hit and Miss" (aciertos y fallos).
Objetivos
Los cálculos integrales utilizan métodos de Monte Carlo para aproximar el valor de una integral particular. Para hacer esto, dividimos el intervalo integral en un número finito de subintervalos y calculamos el valor del integrando en un número aleatorio de puntos en cada subintervalo.
Este informe presenta experimentos computacionales en Python utilizando la tecnica de muestreo y de acierto de Monte Carlo. Estos métodos se utilizan para estimar integrales y resolver problemas de probabilidad.
Marco Teorico
El método Monte Carlo es un método numérico basado en experimentos aleatorios repetidos. Se utiliza para resolver problemas de difícil o imposible solución mediante técnicas analíticas.
El marco teórico del método Monte Carlo se basa en las siguientes ideas. Si un experimento aleatorio se repite suficientes veces, la frecuencia relativa con la que ocurre cada resultado es aproximadamente igual a la probabilidad de ese resultado.
Por ejemplo, si lanza una moneda 100 veces, la frecuencia relativa de cara, o la probabilidad de que salga cara, es aproximadamente la mitad.
En estadística, el método de Monte Carlo se utiliza para generar muestras y poblaciones aleatorias. Para ello se genera un conjunto de números aleatorios según la distribución de la población.
Los métodos de Monte Carlo se pueden utilizar para generar muestras aleatorias a partir de diversas distribuciones, que incluyen:
Ventajas y desventajas del método Monte Carlo
El método Monte Carlo tiene muchas ventajas, entre ellas:
Sin embargo, el método Monte Carlo también tiene algunos inconvenientes:
Problema a resolver
El diagrama a resolver es un cuadrado con cuatro cuartos de círculo en su interior. La longitud de un lado de un cuadrado es 4 y el radio de un círculo es 1.
El área del cuadrado es 4 * 4 = 16.
El área de cada cuarto de círculo es π * 1^2 / 4 = π / 4.
El área del área sombreada es 16 - 4 * π / 4 = 16 - π.
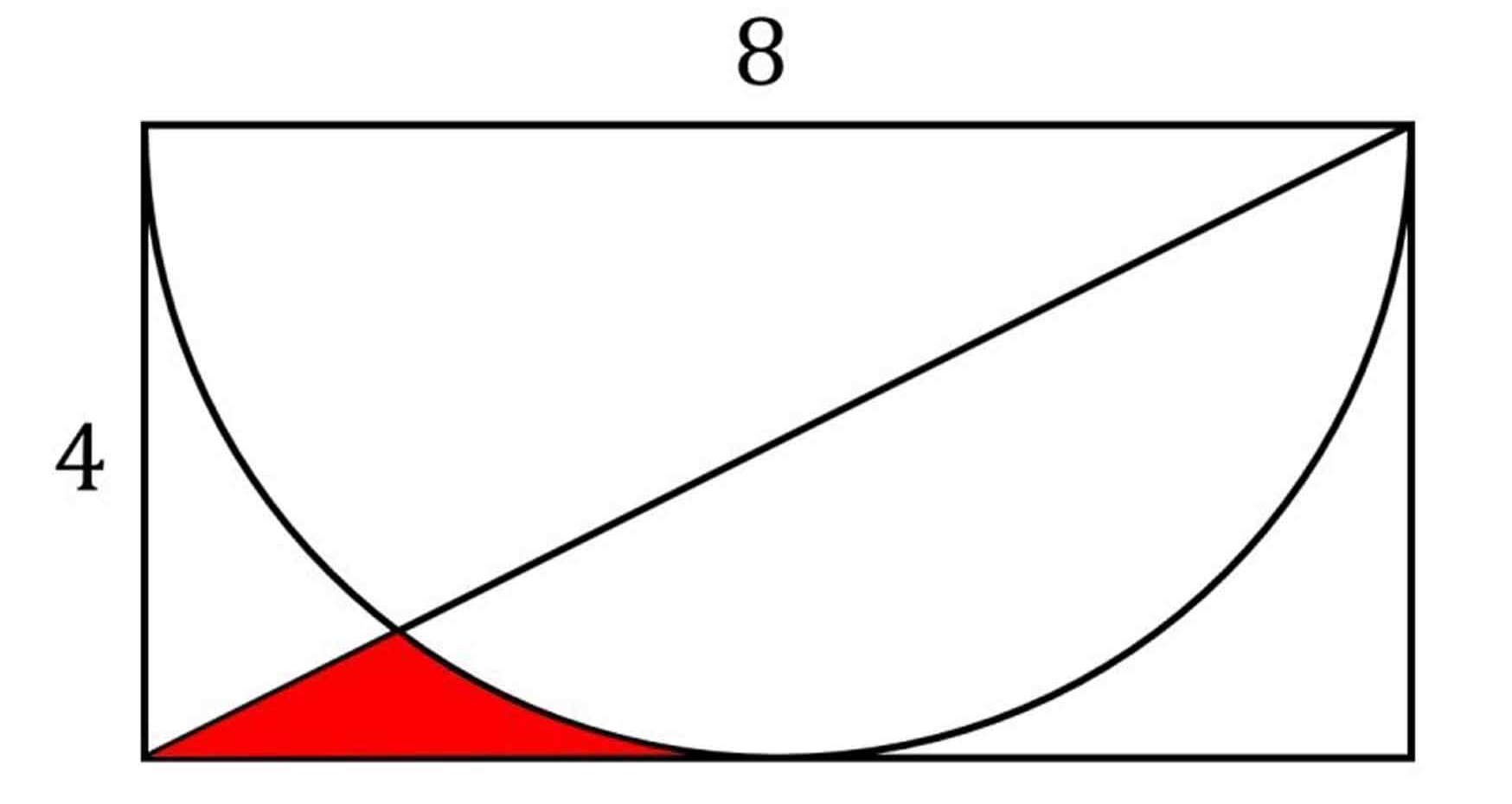
Gracias a la representacion gráfica se puede ver mas facilmente lo que buscamos resolver mediante el metodo de Monte Carlo
Métodos a utilizar
Metodo de muestreo(sampling)
En general, el método de Monte Carlo es un método de cálculo numérico que se basa en la generación de números aleatorios. Se utiliza para resolver problemas que son difíciles o imposibles de resolver mediante métodos analíticos. Este se basa en la siguiente idea:
Es la generación de puntos aleatorios dentro de un dominio específico para aproximar una solución numérica a un problema dado
Para tener una idea mas clara, si nosotros lanzamos una moneda al aire 100 veces, la frecuencia relativa con la que salga cara se aproximará a 1/2, que es la probabilidad de que salga cara.
Dentro del método de Monte Carlo, se utiliza esta idea para estimar valores o probabilidades. Esto se hace generando una gran cantidad de puntos aleatorios y calculando el valor o probabilidad de la función que desea estimar en cada punto. de manera en que el valor estimado se obtiene calculando el promedio de los valores obtenidos en puntos aleatorios y en cuantos más puntos aleatorios se generen, más mucho mas precisa será la estimación. De esta manera los métodos de Monte Carlo se pueden utilizar para resolver una gran cantidad de problemas, los cuales incluyen a los siguientes:
Ventajas del método Monte Carlo
El método Monte Carlo tiene una gran cantidad de ventajas, entre ellas:
Desventajas del método Monte Carlo
Metodo de hit and miss
"Acertar y fallar" o Hit and Miss es un tipo de estimación del área de una región o de cálculo de la integral de una función. A diferencia de los métodos de muestreo, en el método de acierto y error, los puntos aleatorios no se generan dentro de un dominio específico, sino dentro de un dominio más amplio que incluye la región de interés. Luego se verifica cada punto para ver si "llega" a la región de interés, y esta información se utiliza para calcular la estimación.
El método de hit and miss tiene varias ventajas, donde se incluye:
Y de igual manera tiene algunas desventajas:
Solucion
Para generar la solucion de este ejercicio debemos de ir desde lo mas sencillo hasta lo mas complicado, de manera en que logremos tener una vision mas real del ejercicio, para ello empezaremos realizando un modelo computacional de lo que pudimos ver anteriormente
Run to view results
Entonces, para comprender de mejor manera el codigo tendremos que aclarar lo siguiente:
"X" y "Y" se definen como arreglos espaciados linealmente entre 0 y 8 para x y entre 0 y 4 para y. Estos rangos representan los valores a lo largo de los ejes x e y dentro de el gráfico.
Creación de Malla:
"np.meshgrid" es una funcion de la libreria que importamos al inicio del codigo llamada "NumPy" se utiliza para crear una malla bidimensional (X e Y) a partir de los arreglos x e y. Esta malla será utilizada para evaluar las funciones en cada punto. Ahora para definir las funcione, lo hacemos de la siguiente manera: Definiremos F1 y F2 en términos de X e Y. Estas funciones representan las ecuaciones de contorno que se quieren graficar. Creación de la Figura y los Ejes:
Gracias a eso podemos definir de manera computacional el grafico que teniamos anteriormente y podemos encontrar un alto similar entre ellos
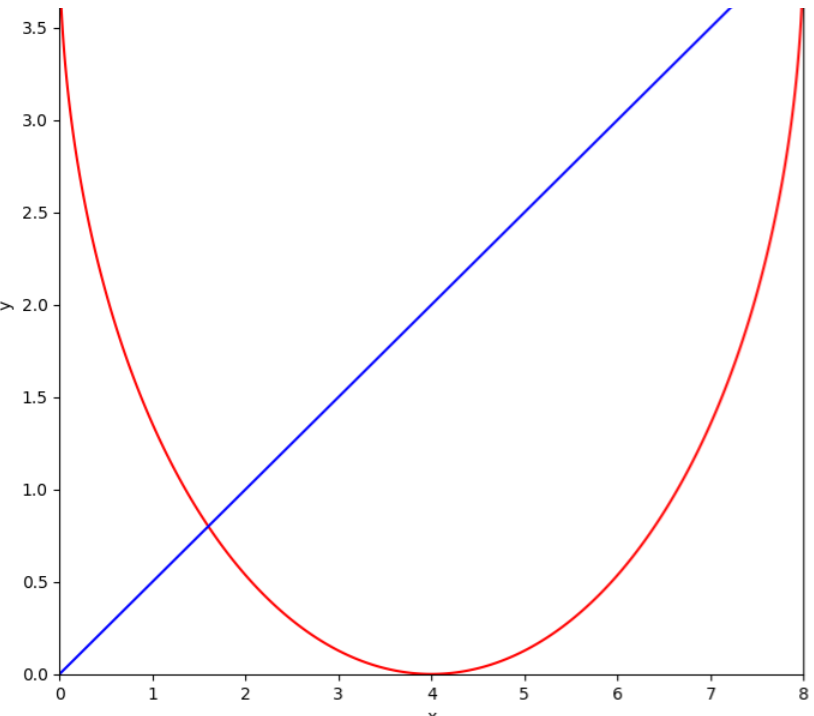
Una vez que realizamos la figura, ahora falta econtrar la manera de aislar y tener en cuenta solamente el area sombreada
Run to view results
Dentro de este nuevo grafico realizamos una acciones nuevas
Rellenar el Área Bajo la Curva: La misma que se encuentra la intersección de las funciones y se crea un área sombreada bajo la curva de la función F2 en el dominio especificado. Esta área está sombreada en rojo utilizando ax.fill_between. Resaltandola de la siguiente manera
Run to view results
Como podemos ver ya tenemos toda el area del ejercicio marcada, pero ahora necesitamos marcar el area especifica en el cual se va a trabajar, y eso lo realizamos de la siguiente manera
Run to view results
Una vez definida un area el cual vamos a calcular, debemos encontrar dos areas las cuales son el area debajo del circulo y el area debajo de la linea que atraviesa el circulo, para empezar con uno de los metodos que vamos a aplicar dentro de este informe
Run to view results
Una vez definido el area donde trabajaremos podemos comenzar con el primer metodo
Metodo de Hit and Miss
Como mencionamos anteriormente el metodo de Hit and Miss es diferencia de los métodos de muestreo, en el método de acierto y error, los puntos aleatorios no se generan dentro de un dominio específico, sino dentro de un dominio más amplio que incluye la región de interés.
Entonces para hacer esto, realizaremos de la siguiente manera:
Run to view results
Dentro del codigo hacemos lo siguiente:
Run to view results
Ahora implementamos una nueva funcion la cual nos ayuda a:
verificar si un Punto está Debajo de la Curva:
de la siguiente manera below_curve(x, y): Verifica si un punto (x, y) está debajo de la línea o el semicírculo, dependiendo de la ubicación en el eje x.
De igual manera tenemos una funcion para ejecutar diferentes iteraciones para Diferentes Valores de n:
t_muestras = [10, 100, 100000]: Define una lista de diferentes tamaños de muestra. Para cada valor en t_muestras, se ejecuta el método de Hit and Miss y se calcula el área utilizando los puntos generados. Imprime las áreas obtenidas para cada tamaño de muestra.
Con estas iteraciones es una herramienta para analizar cómo la variación en el tamaño de muestra afecta la precisión de la estimación del área bajo la curva utilizando el método de Hit and Miss. Permite entender cómo la cantidad de datos aleatorios afecta la calidad de la aproximación numérica del área deseada.
Entonces nosotros lo hacemos de la siguiente manera
1.-Lista de Tamaños de Muestra: t_muestras = [10, 100, 100000]: Definimos tres tamañosdiferentes. donde caada valor en esta lista representa cuántos puntos aleatorios se generarán para estimar el área.
2.-Iteración y Cálculo del Área: Para cada valor en t_muestras (por ejemplo, 10, 100, 100000): Se ejecuta el método de Hit and Miss (hit_and_miss(a, b, c, n)) con el tamaño de muestra actual de ( n). De esta manera los puntos generados aleatoriamente se usan para calcular el area bajo del circulo.
Entonces siempre debemos tomar en cuenta que la precisión de la estimación del área mejora a medida que aumenta el tamaño de muestra.
Run to view results
Ahora buscaremos los puntos que se encuentran fuera de circulo
Run to view results
aqui implementamos un cambio a la funcion below_curve de manera en que below_curve(x, y): Verifica si un punto (x,y) está debajo de la línea o el semicírculo, dependiendo de la ubicación en el eje x. Gracias esto podemos saber si es que esta dentro de o fuera de la region sombreada que buscamos calcular
Para obtener el boceto final de la siguiente forma
Run to view results
Metodo de Sampling
Como mencionamos en este informe el metodo de samplling , En general, el método de Monte Carlo es un método de cálculo numérico que se basa en la generación de números aleatorios. Se utiliza para resolver problemas que son difíciles o imposibles de resolver mediante métodos analíticos. Este se basa en la siguiente idea:
Es la generación de puntos aleatorios dentro de un dominio específico para aproximar una solución numérica a un problema dado
Entonces como ya hemos definido el area en el que vamos a trabajar este metodo se puede desarrollar de manera mas facil, y rapida, para ello lo realizamos de la siguiente
Dentro de este nuevo codigo podemos ver la siguiente funcion
Run to view results
La misma que es utilizada para definir una linea mediante una funcion lineal, que en este caso es igual a y = 0.5 * x
Ahora mediante el siguiente codigo definimos el area del semicirculo de la siguiente manera
Run to view results
De esta forma controlamos el area del semicirculo mediante un rango que esta entre 1.6 y 4., La ecuación del semicírculo está diseñada para representar la mitad superior de un círculo con un radio de 2
Ahora generamos nuevos datos dentro del rango
Run to view results
Ahora crearemos la funcion de sampling la cual nos permitira la generacion de puntos de manera aleatorioa y su separacion entre puntos encima de la curva y puntos debajo de la curva
Run to view results
Esta region se vera representada por el area del cuadrado
Run to view results
Una vez que tenemos todo, solo faltara ejecutar el codigo y ver el resultado
Run to view results
Como podemos ver en el resultado, el area no se asemeja al area del ejercicio por ende es necesario realizar mas pruebas y simulaciones, ahora lo que intentaremos hacer es encontrar los puntos que se encuentran fuera tanto del semicirculo como de la linea recta de la siguiente manera
Run to view results
Agregaremos una nuevas funciones las mismas que verifican si un punto está debajo de la recta o del semicírculo, respectivamente., y ademas, hemos ajustado la función de sampling para separar los puntos que están debajo de la recta y del semicírculo.
Una vez completado esto, debemos tomar en cuenta solo los puntos que se encuentran en la region que deseamos
Run to view results
Entonces como resumen, nosotros generamos puntos aleatorios en un cuadrado y determinamos si cada punto está debajo de la línea o del semicírculo. Luego, se calcula el área estimada en función de la proporción de puntos que se encuenctran debajo de las curvas en comparación con el área total del cuadrado. y de esta manera visualización final que obtenemos muestra las funciones y los puntos generados, diferenciando entre puntos dentro y fuera de las curvas. Obteniendo la respuesta correcta y resaltando el area esperado
Run to view results
Ahora como metodo de representacion utilizamos la tabla, la misma que nos muestra como cambia el area de la curva segun la muestra que tenemos y imprimimos los puntos que no se encuentran dentro de ninguno de los dos
Run to view results
Este código crea dos gráficos: uno para representar la variación del área bajo la curva con el tamaño de la muestra y otro para la cantidad de puntos fuera de las curvas. Como podemos ver en la grafica los resultados son casi iguales con pequeñas variciones