Amazon S3
With the S3 integration, you can access the files in your S3 buckets directly in Deepnote. The files will be accessible via the filesystem, so you can work with your data as if you had it locally.
How to connect to S3
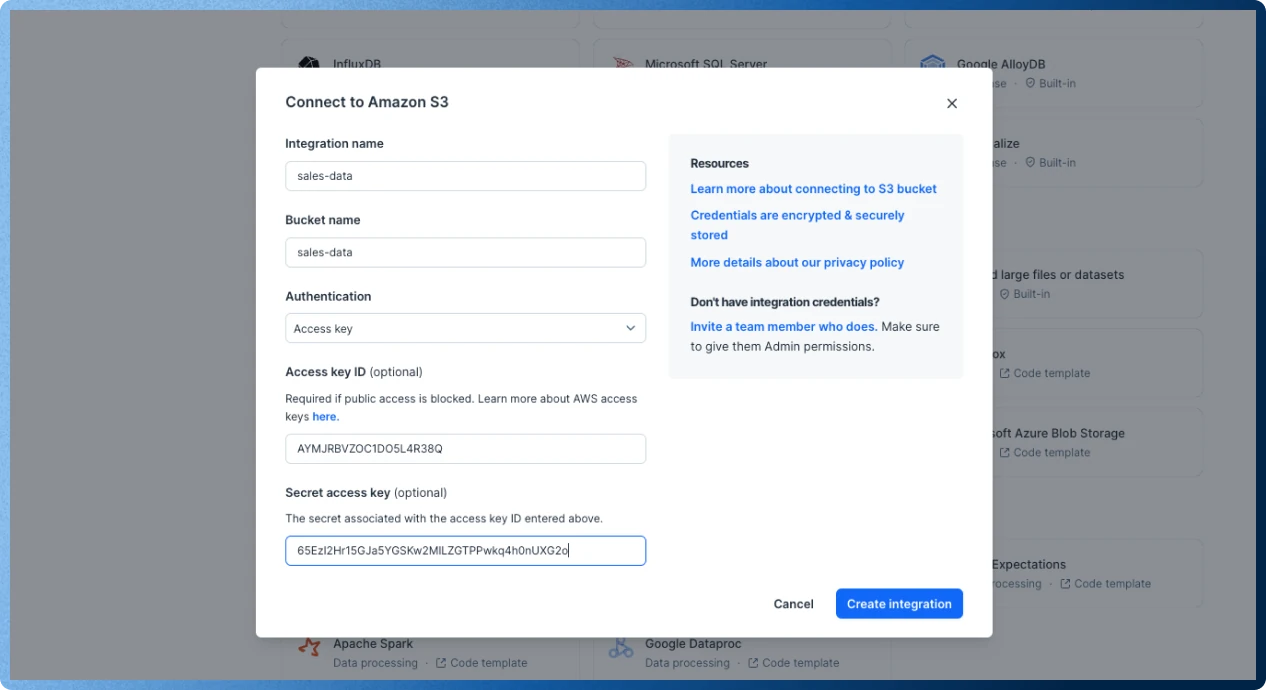
First, you will need to create a S3 bucket or have access to an existing one.
To add a connection to an AWS S3 bucket in Deepnote, go to Integrations via the left-hand sidebar, then create a new S3 integration.
If the bucket is publicly accessible, you will only need to enter:
- A name for your integration
- The name of the S3 bucket
For private buckets, you will also need to add your:
- Access key ID
- Secret access key
You can learn how to create these credentials here.
Authenticating using an IAM role
Using an IAM role instead of access keys to connect to an S3 bucket is preferred for enhanced security and making it easier to manage. IAM roles offer temporary credentials that automatically rotate, reducing the risk of long-term credential exposure. This approach also simplifies permissions management, allowing for more granular access control to S3 resources based on the principle of least privilege. Moreover, it eliminates the need to store static credentials, reducing the potential for security breaches.
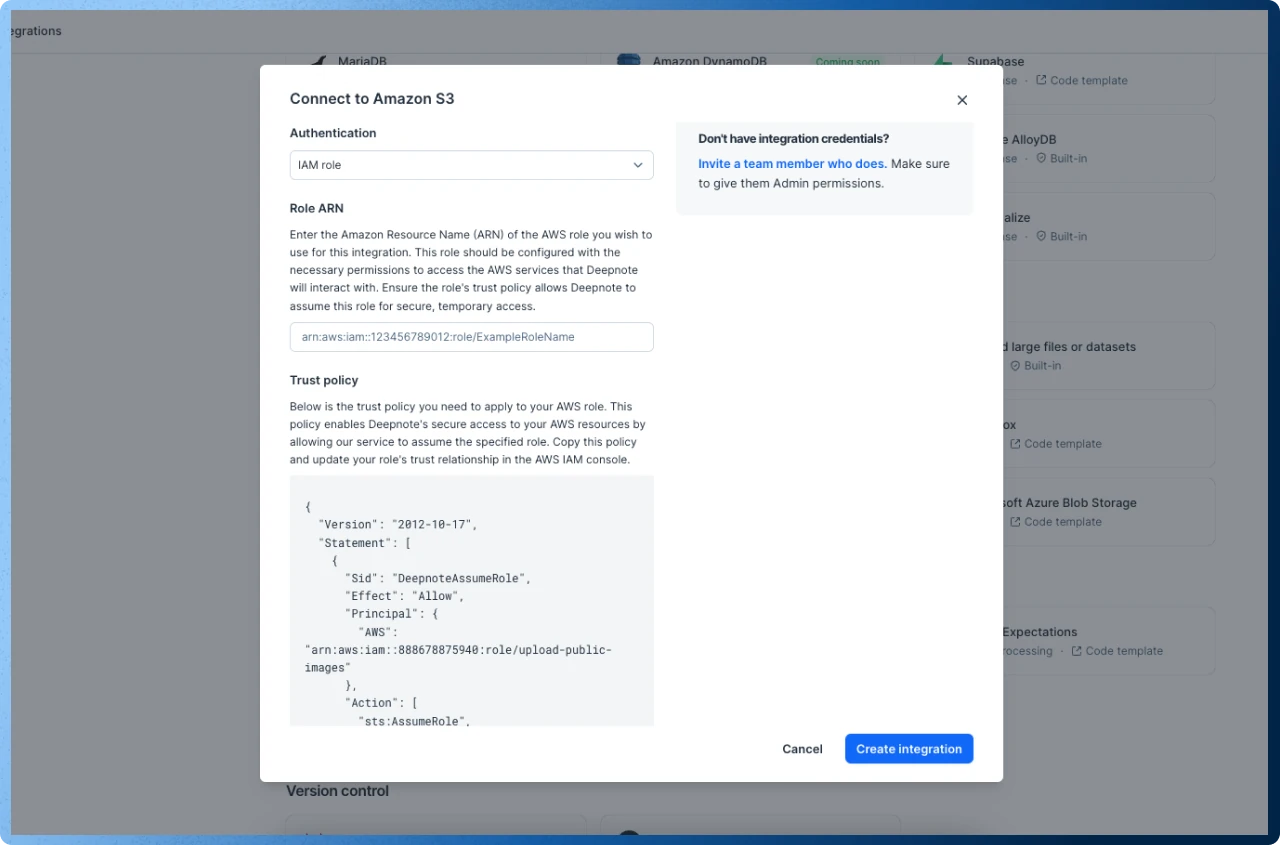
In the "Authentication" section, select the IAM role option in the dropdown menu.
Enter the Amazon Resource Name (ARN) of the AWS role you wish to use for this integration. This role should be configured with the necessary permissions to access the S3 bucket that Deepnote will interact with.
To allow Deepnote to access your S3 bucket, you will need to update the role's trust policy. Copy the generated trust policy and update your role's trust relationship in the AWS IAM console.
How to use S3 in your notebook
Once you have connected the S3 integration to your project, you can access the files in your bucket under the path /datasets/{integration name}.
If the name of your integration is sales-data, you can list the files in the bucket by adding a code block with the following content:
!ls /datasets/sales-data
You can access the files in your S3 bucket as if they were regular files.
import pandas as pd
# Read the CSV file
df = pd.read_csv('/datasets/sales-data/june.csv')
# Display the DataFrame
df