Databricks
With the Databricks integration, you can leverage the capabilities of Deepnote's SQL blocks to query your warehouses at lightning-fast speed.
Deepnote's Databricks integration allows data teams to efficiently query their data, extract relevant data, and start analyzing and modeling in the comfort of their known notebook environment.
How to connect to Databricks
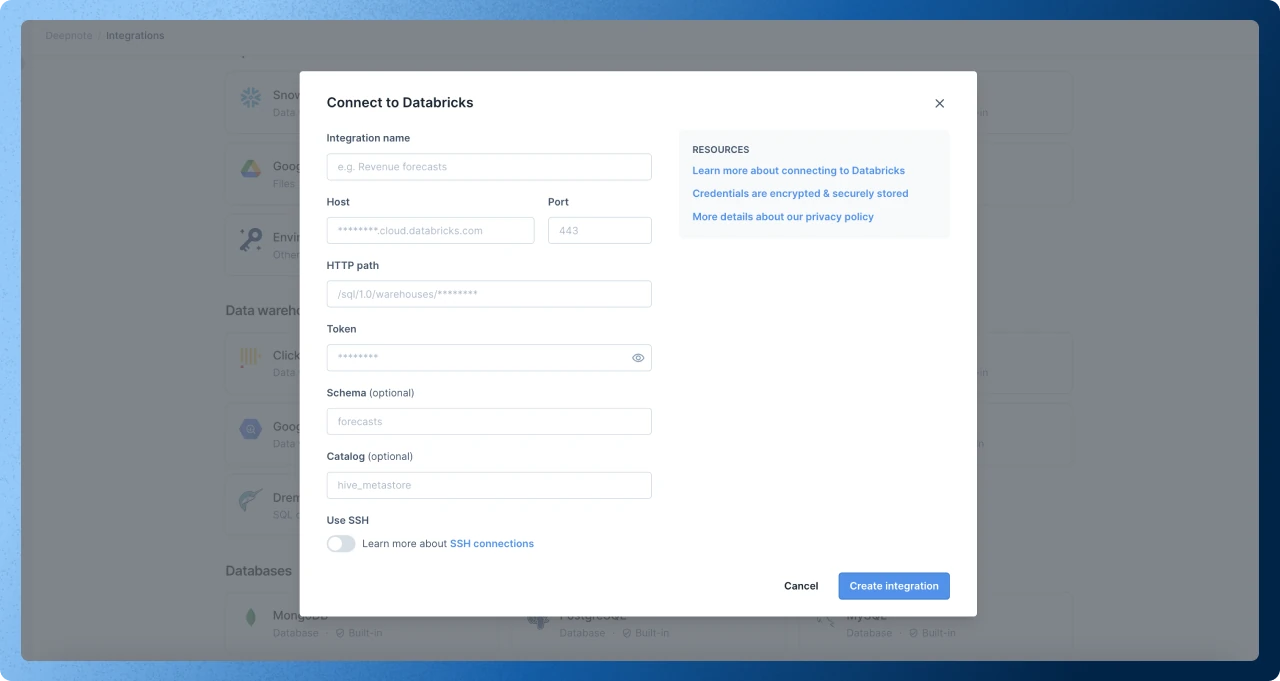
To create the integration, you'll need a few things. Follow Databricks guide to get the connection details for a SQL warehouse.
- Host: Databricks server hostname. The hostname of the server you are trying to connect to.
- Port: The port on the server of interest you are trying to connect to. The default is port 433.
- HTTP Path: Databricks compute resources URL.
- Token: Your personal access token. For instructions about how to generate a token, see Databricks docs.
- Schema: Default schema used by integration. This is equivalent to running
USE <schema_name>. If you provide no schema the default isdefault. - Catalog: Default catalog used by integration. If you provide no name the default is
hive_metastore.
How to use
Once created, you'll be able to connect the Databricks integration to any project within your workspace through the right-hand sidebar. The Databricks integration comes with custom Databricks SQL blocks that help streamline your analytics efforts. You can also convert any existing SQL block to a Databricks block.
As with all SQL blocks, the query results will be saved as a Pandas DataFrame and stored in the variable specified in the SQL block.
In order to enable the SQL blocks to work with Databricks integration, you have to install sqlalchemy-databricks in your project. Run the following command in a block to get it installed:
!pip install sqlalchemy-databricks
Or, alternatively, add it to local Dockerfile and it will get automatically installed and cached for faster project starts.
Next steps
Jump right into Deepnote & learn more about SQL blocks in this A/B testing template. You can also save yourself some setup work by hitting the Duplicate button in the top-right corner to start exploring on your own!
Secure connections
Deepnote supports securing connections to Databricks via optional SSH tunnels.