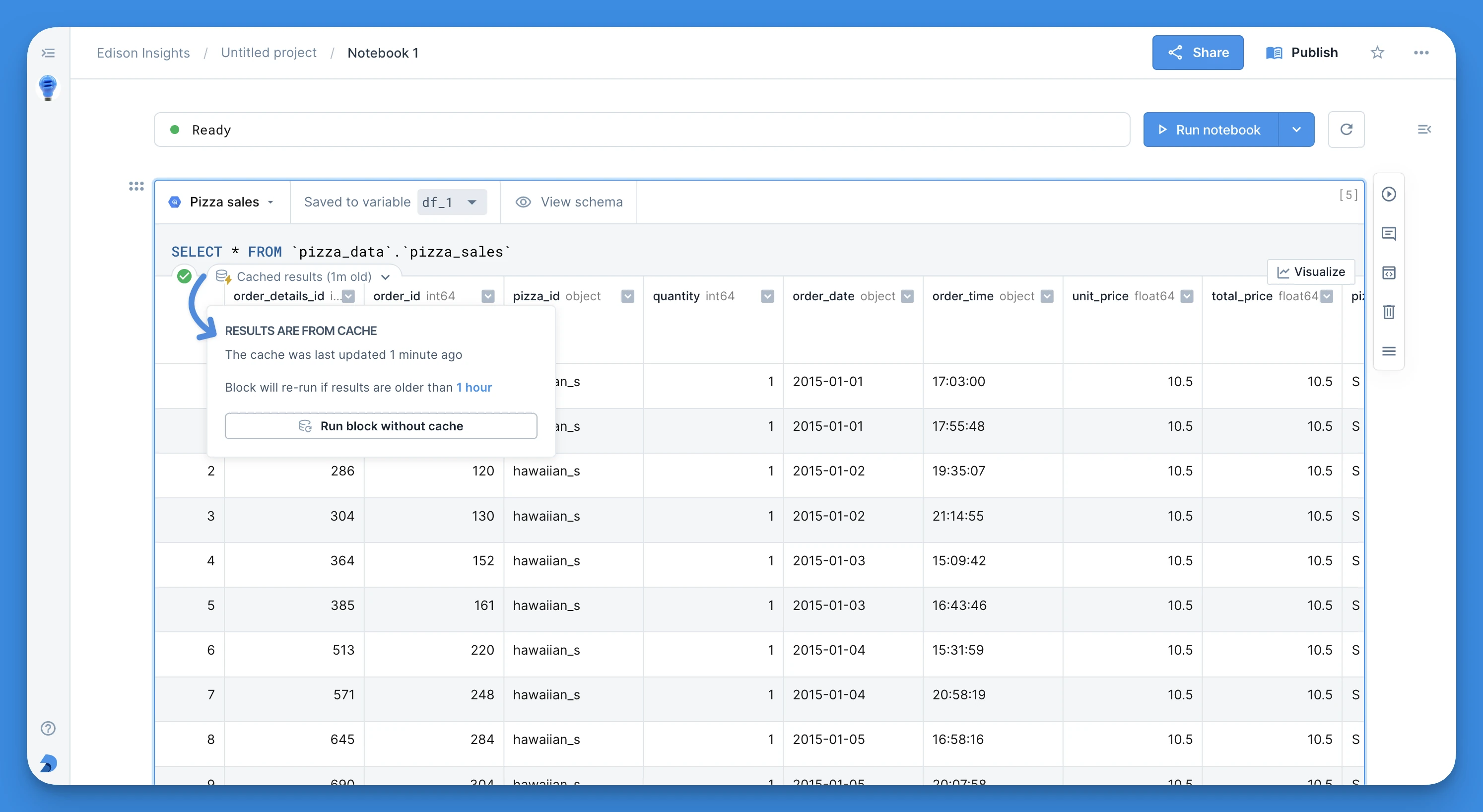
SQL query caching
Speed up your notebooks and control data warehouse costs with query caching.
With caching enabled, Deepnote automatically saves the results of your queries in SQL blocks. Returning these cached results for repeated queries can greatly improve performance in your notebooks and reduce the load on your database/warehouse.
Main benefits:
- Improved performance: By utilizing cached results, you can experience significantly faster SQL execution times, as data is retrieved from the cache instead of querying the warehouse repeatedly. With lightning-fast queries, you can focus more on your data analysis instead of waiting around for results to arrive.
- Reduced database load: Caching minimizes the number of queries sent to the warehouse, reducing the load on the database and giving you better control over your query costs.
How to enable caching
1. Saving cached results
In order to take advantage of SQL caching, you need to have this feature enabled for your workspace. Go to Settings & Members and click on Project settings.
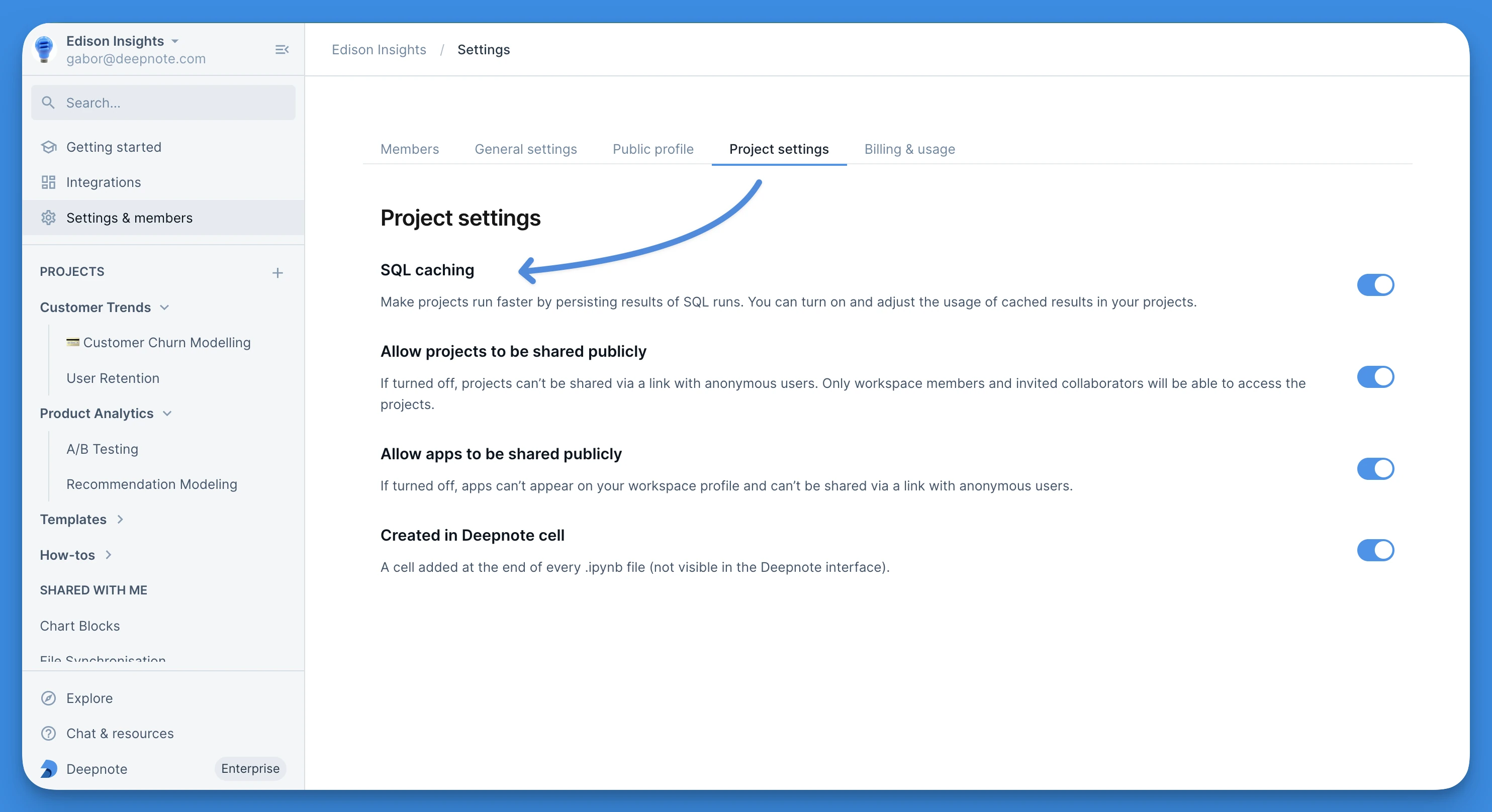
When SQL caching is turned on (default state), the results of all your SQL block queries are automatically stored in the cache. This process happens seamlessly in the background without affecting the visibility of cached results. It's important to note that you will only see cached results returning in your SQL blocks if you specifically enable their usage within the project you are working on.
When the setting is turned off, query results are not saved to the cache, and the option to use cached results is disabled across all projects in the workspace.
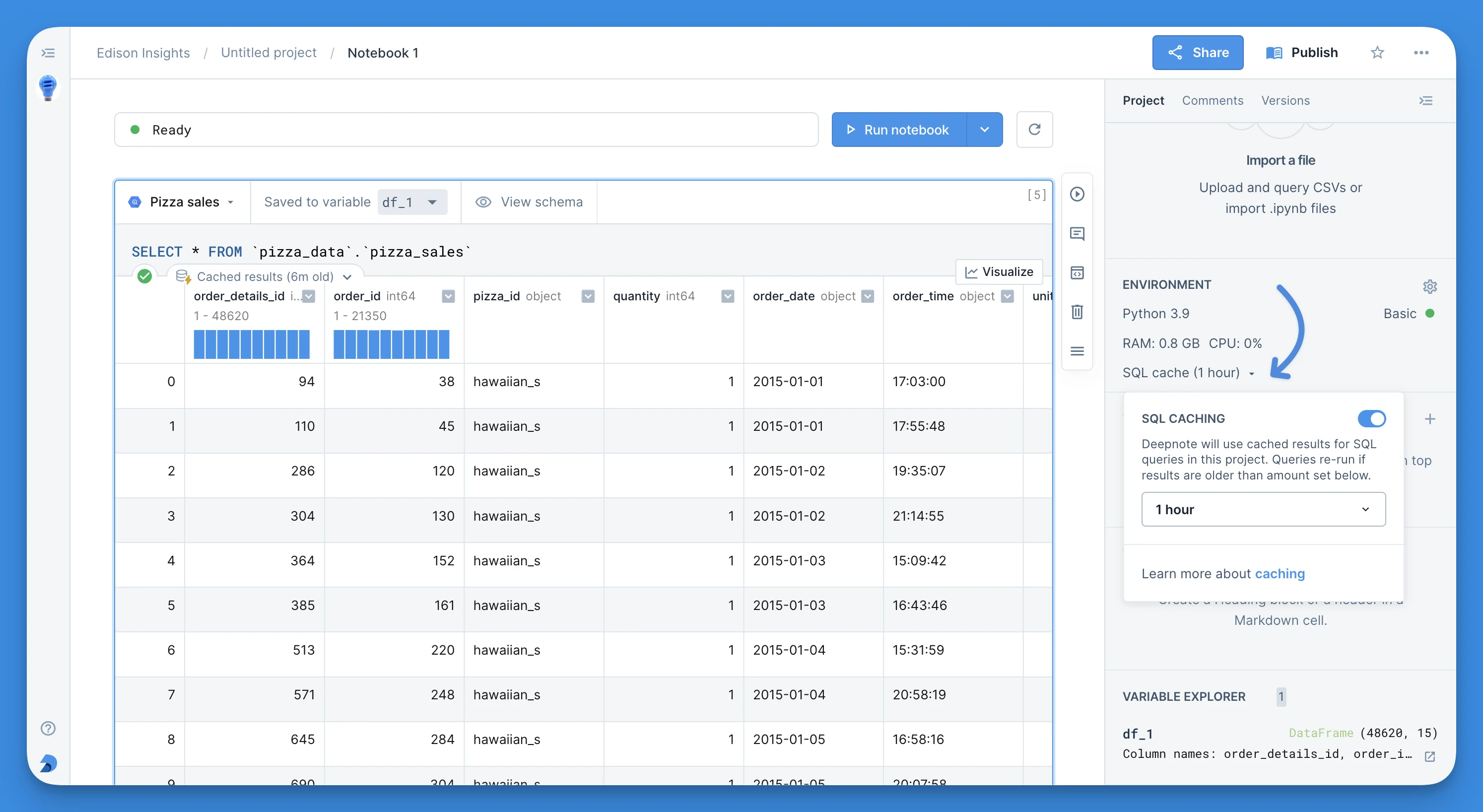
2. Surfacing cached results
To turn on the usage of cached results, navigate to the Environment section in the right-hand sidebar of the project and toggle the SQL cache setting to on. This enables returning cached results for all SQL blocks across all integrations in that project.
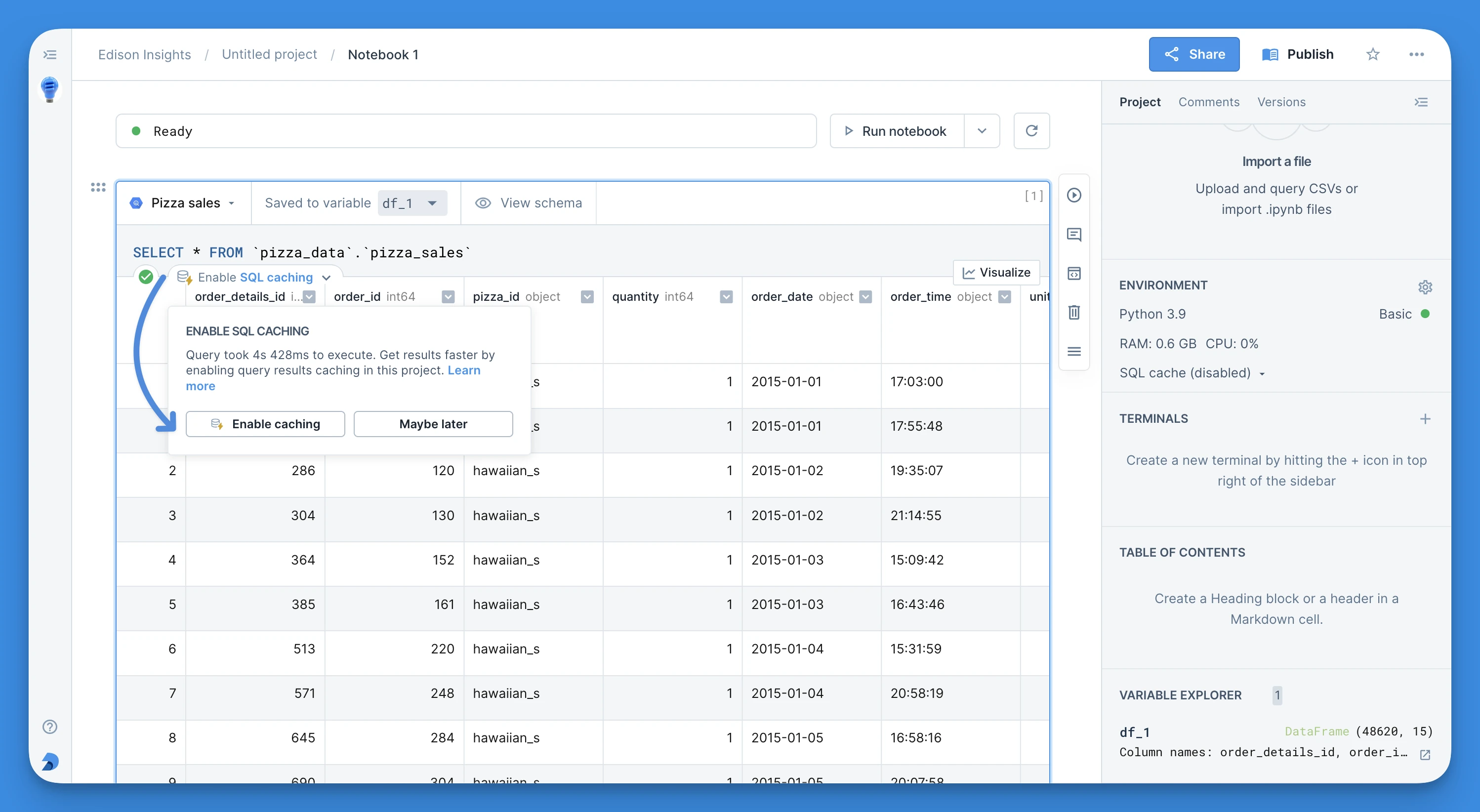
Alternatively, when you run longer queries in a project with caching disabled, Deepnote will offer you a convenient shortcut to turn on the usage of cache for the given project right from the given SQL block.
How does caching work?
When you run a SQL block in a project where caching is enabled, we check if there is a cached result that is not older than the project’s cache expiration period (1 day by default).
- If a recent cached result is available, the query is not sent to the warehouse. Instead, the cached result is pulled into memory and displayed in the DataFrame table.
- If there are no cached results or the cached results are older than the project’s cache expiration period, the query is executed against the warehouse, and the results are saved to the cache.
You can control how often you wish to fetch fresh data for the given project by changing the project’s cache expiration period in the SQL cache settings. For instance, if you only wish to hit your warehouse once a week, you can set it to one week.
Block execution without cache
When caching is enabled for a project, running the whole notebook or executing individual SQL blocks will always attempt to use cached results. However, you can override this behaviour and force re-execution of the query against the warehouse in two ways:
- In the dropdown options of the Run notebook button, select Run notebook without cache to execute the notebook without utilizing cached results.
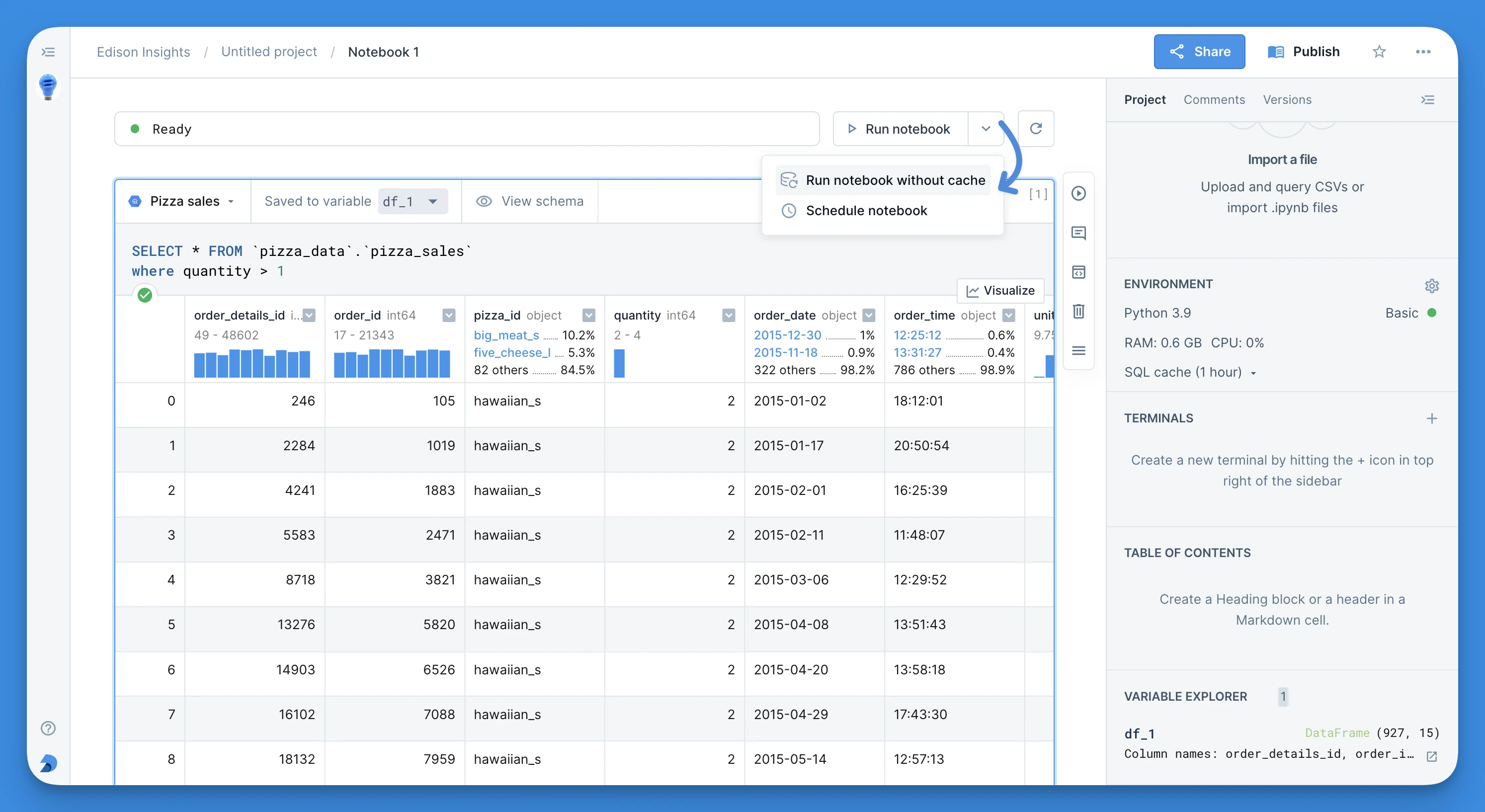
- In the block sidebar, select Run without cache. Clicking on this option forces the specific SQL block to pull fresh results from the warehouse.
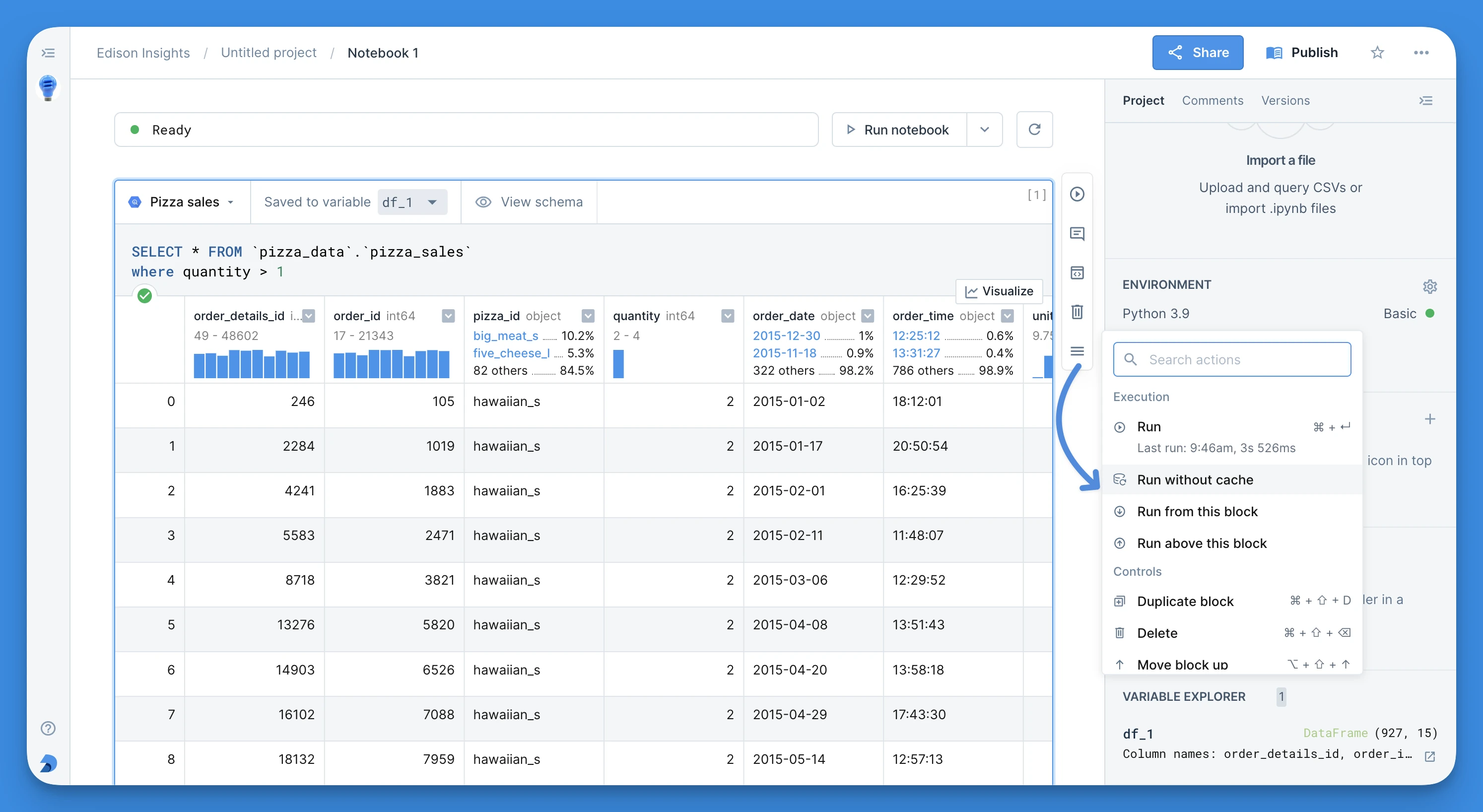
These options are only displayed if project-level caching is enabled.
Exceptions
Caching has the following limitations: - If the returned result is larger than 5GB, caching won’t be applied to that given query. - Caching only works for SQL blocks connected to integrations; DataFrame SQL blocks do not utilize the cache. - Caching is disabled for integrations that uses OAuth for authentication.
In addition, while query caching offers great benefits, there may be specific scenarios where relying on caching may not be ideal.
If you work on projects where freshness of data is crucial, such as analyzing (near) realtime data or checking the results of recent data manipulations in your warehouse. You can mitigate against unexpected results by forcing re-execution without cache or turning off caching for the given project.
When you use non-deterministic functions in your SQL queries. For example, date and time functions such as CURRENT_TIMESTAMP() and CURRENT_DATE, and other functions such as SESSION_USER(). These functions generate different values depending on the time of execution and caching cannot take that into account.
Potential workarounds for these cases include: - Using Python variables in your SQL queries instead of native SQL functions. These will evaluate before sending the query therefore cached results will be saved for each unique value. - Setting lower cache expiry periods in your project. For instance, if you have a 1 hour expiry set, using CURRENT_DATE in your SQL query is a suitable option. - Turning off caching in your project.
Data Retention
We automatically remove any cached data after 30 days.