Schema browser
Explore the structure of your data with Deepnote's built-in schema browser.
Exploring the structure of your databases
What comes before a great query? A thoughtful, high-level exploration of your database's tables and columns. Our native schema browser makes it easy to navigate the structure of your data warehouse/database, directly from the notebook. It also features a number of handy shortcut actions which can help you compose your SQL queries more efficiently.
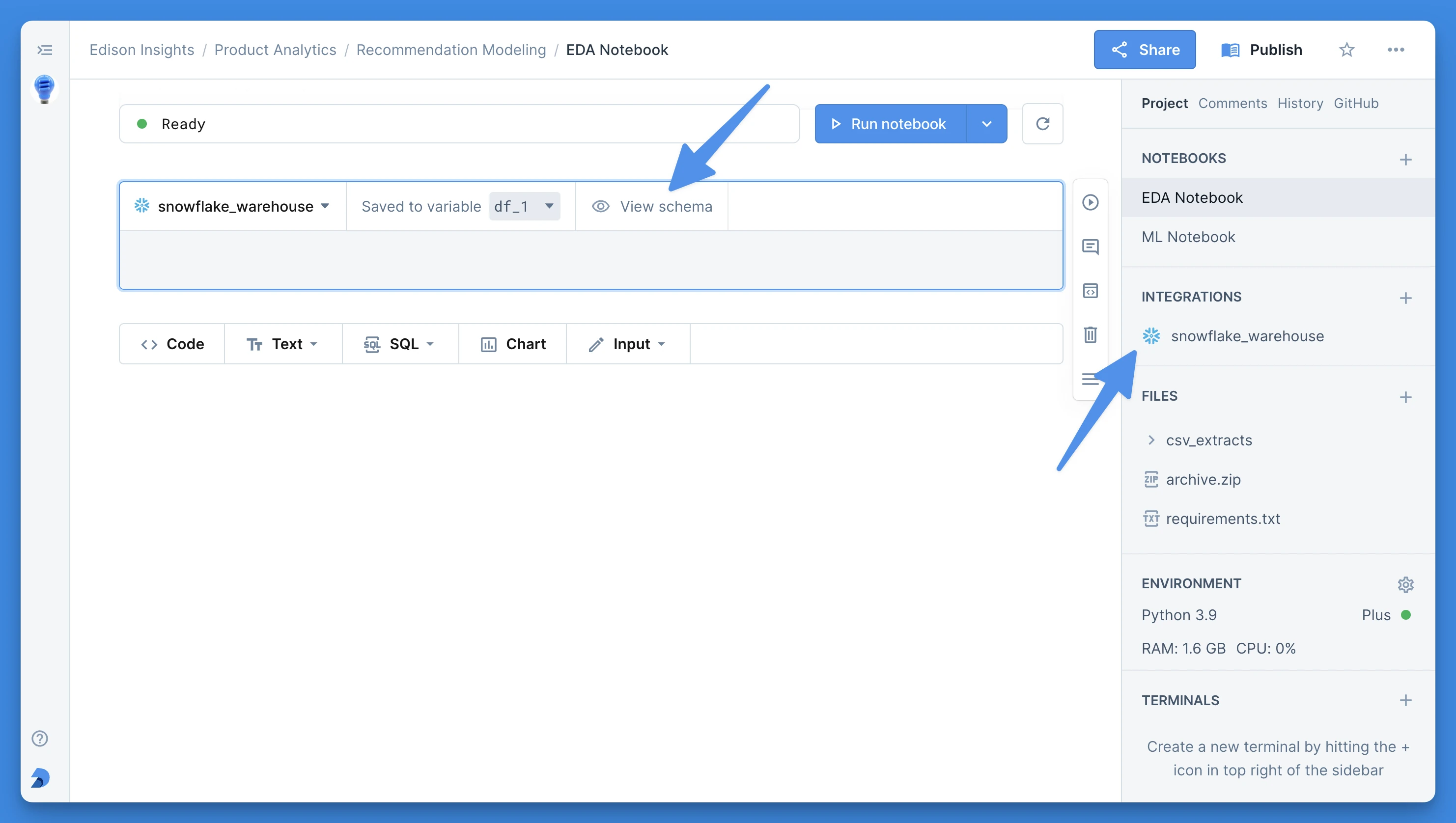
Opening the schema browser
Once you have connected a data warehouse or database to your project, you can open the schema browser in two ways.
- Add an SQL block to the notebook and click on the block’s View schema button.
- Alternatively, you can click on a connected integration in the Integrations section in the right side bar.
Navigating the schema
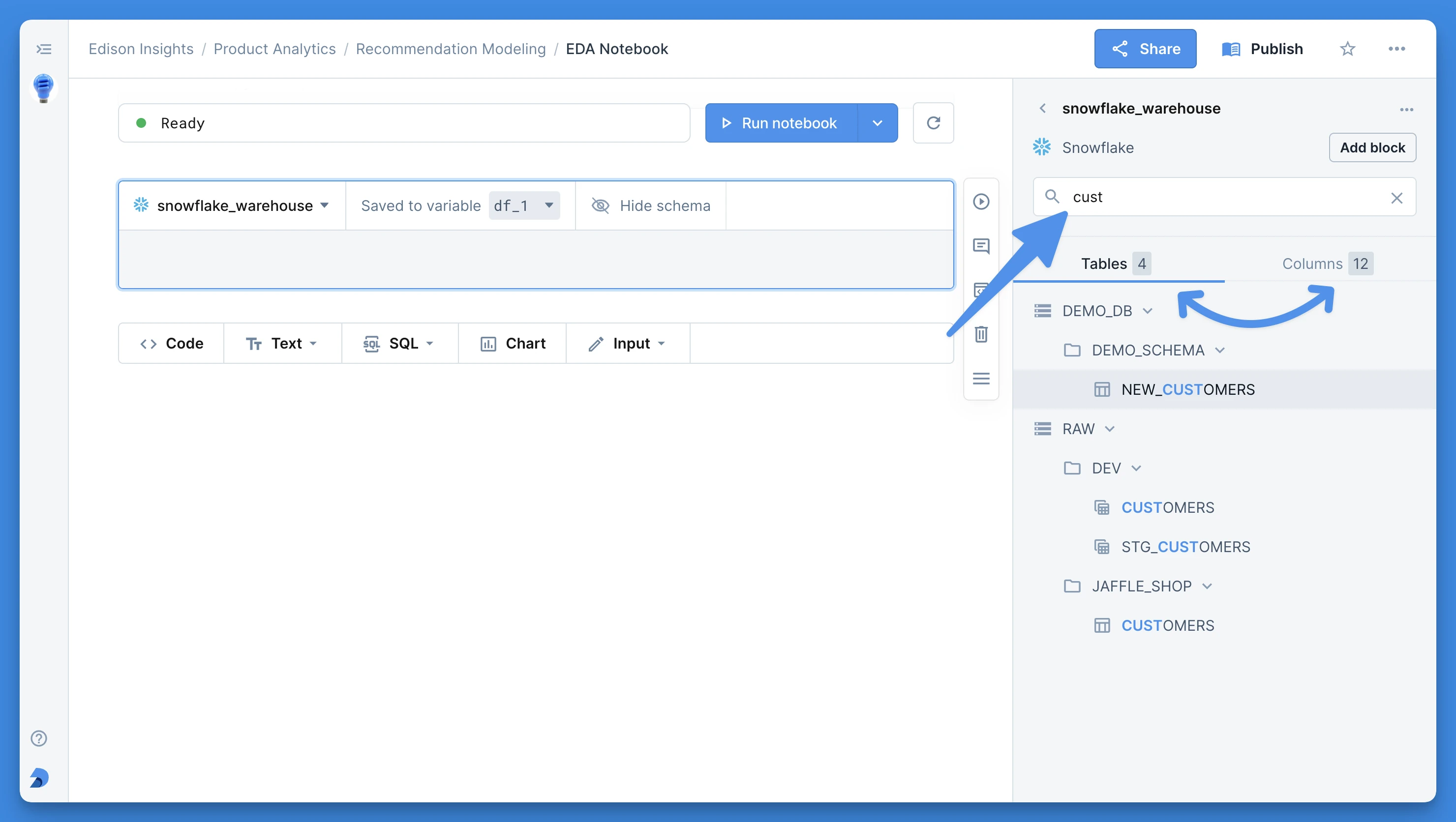
The schema browser has three main components: the search bar, the schema tree, and the table details.
Search bar
Simply start typing to find matching tables and columns from across all your databases and schemas within the given integration. The matching items will be highlighted in the search results. The search results are divided into two separate tabs: tables and columns.
Once you click on a result, the corresponding table’s info will open up in the table details panel at the bottom.
Schema tree
You can freely navigate your schema by opening and collapsing the various objects. Click on a table to view its columns and other details in the table details panel.
You can also access other useful table actions via the context menu when you hover over a table. For example,
- Query table: adds a new SQL block to your notebook with a pre-populated query for the given table (shown below). This is particularly useful for quickly previewing the contents of the table.
- Copy qualified table name: copies the name of the table to your clipboard including its full path in the schema. You can then simply insert it into your SQL block to start querying the table.
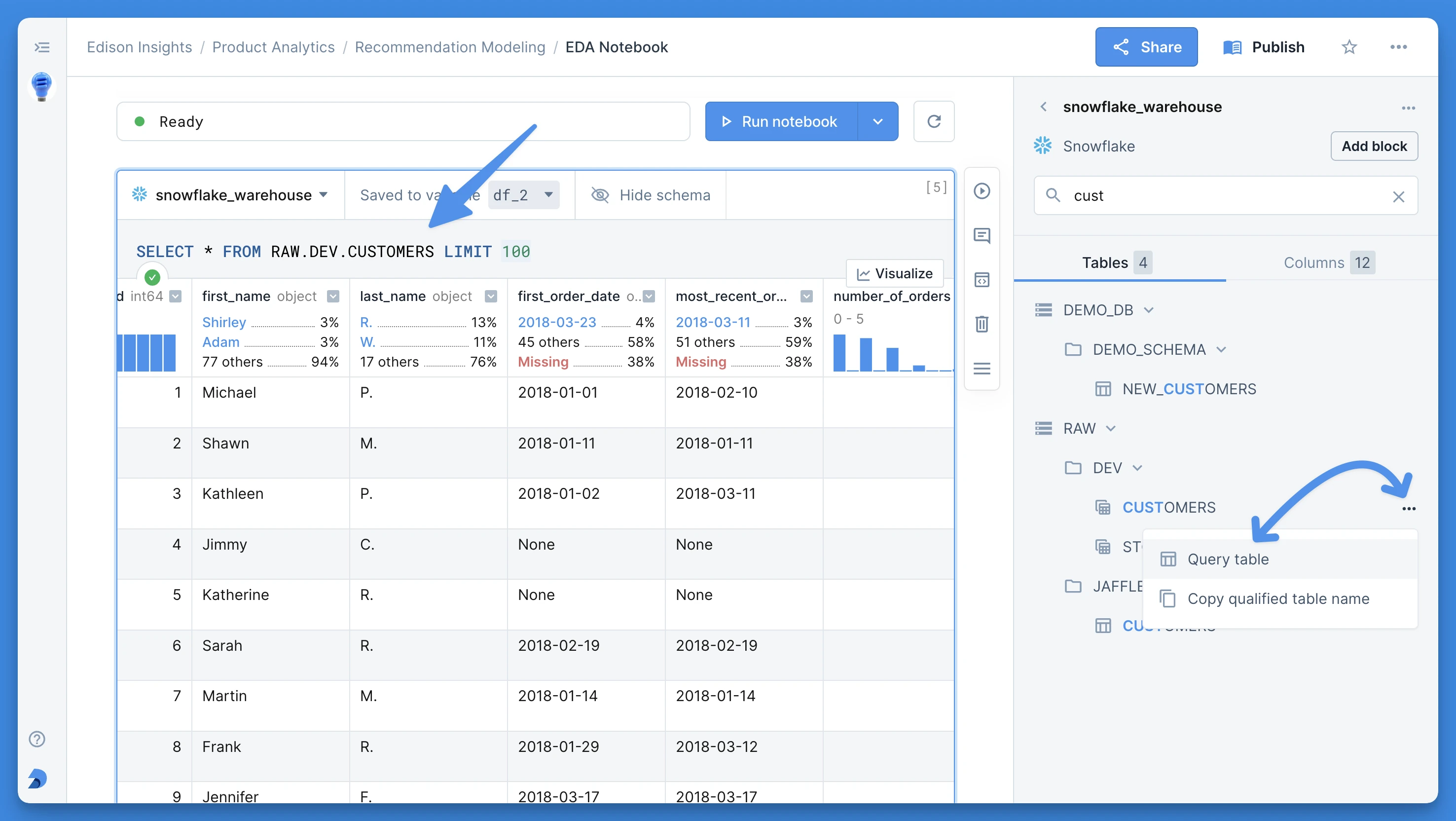
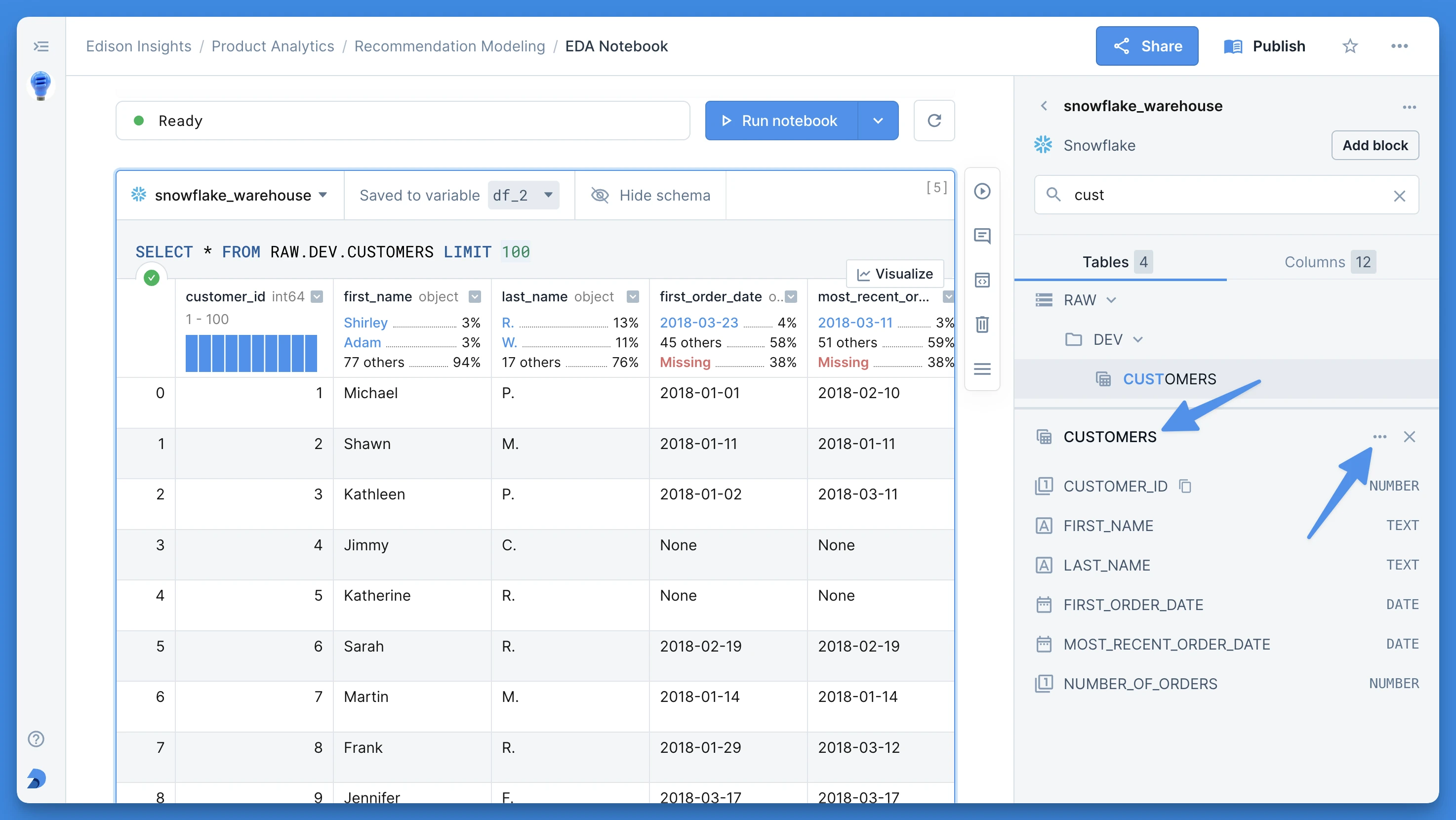
Table details
The bottom panel shows you details about the selected table.
You can see a list of all the columns and their associated data types. You can hover over a column and click on the copy icon to copy the column’s name to the clipboard.
The context menu in the upper right corner offers helpful table actions. These are identical to those available in the schema tree, with a couple of additions:
- Copy all columns: copy a list of comma-separated columns names
- Go to table in tree view: clicking on this will navigate to the table in the schema tree. This can be useful if you opened a table in the search results and would like to quickly jump to its place within your schema hierarchy.
Refreshing the schema
To provide a fast and seamless experience, the schema for a given integration is downloaded and stored by Deepnote after it is first opened. By default, this cached version will be served whenever a workspace member visits the schema browser.
The cached version is retained for 7 days (or until the integration details are changed). After this expiration date, we automatically re-fetch the latest state of the schema when someone views the schema browser.
If you need to access the freshest schema for your work, you can manually force an update. Click on the context menu displayed in the integration’s header and select Refresh.