SQL blocks
SQL is a first-class citizen in Deepnote
Getting started with SQL blocks
To make it easier to query databases, data warehouses or even CSV files, Deepnote offers native way to write and execute SQL code through SQL blocks. After connecting your data source to Deepnote (for example PostgreSQL, Redshift, BigQuery, or Snowflake), you can create SQL blocks in your notebook and begin writing SQL queries or generate them with AI.
When you run a SQL block, Deepnote executes the query and stores the full result in a DataFrame object by default. Features like query caching, query chaining and AI autocompletions make SQL blocks even more powerful convenient to use.
To get started:
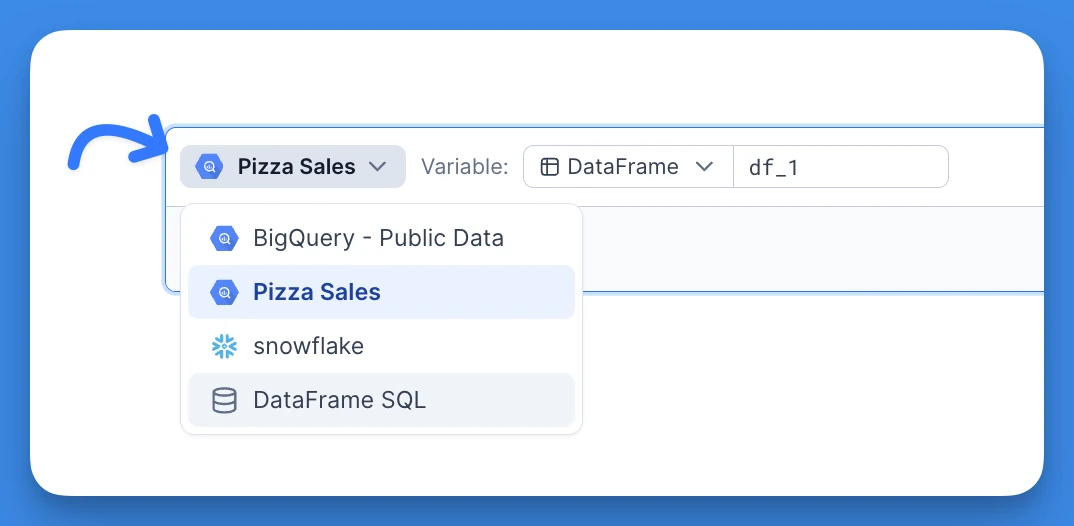
- Create a SQL block from the block adder (or by uploading a CSV file)
- Select the data source you want to query
- Name the results variable
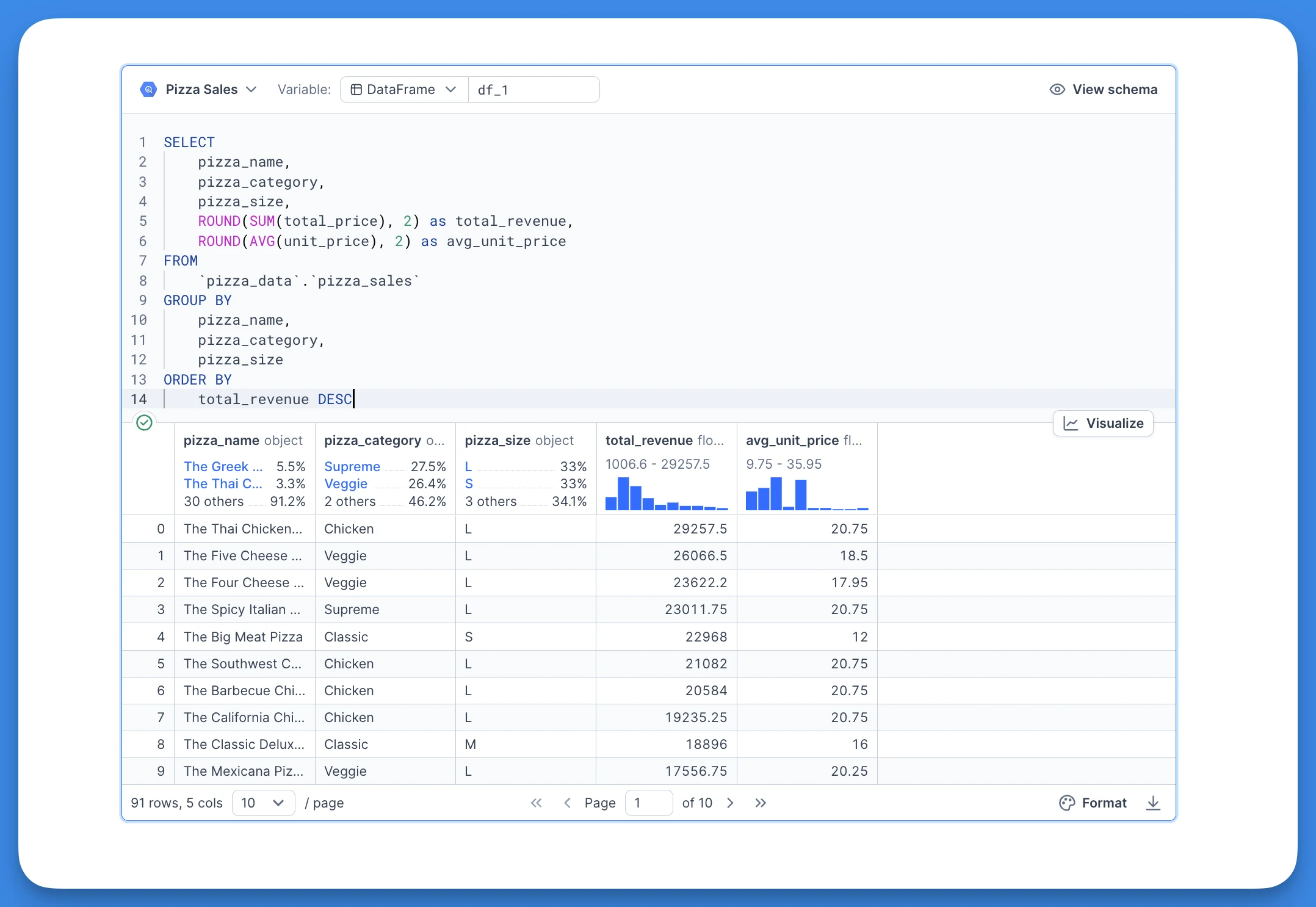
Dataframe SQL
Apart from querying a database, you can also use SQL blocks to query your DataFrames or even tabular files like CSV or Excel. To do that, create a SQL block and select the "DataFrame SQL" option as the data source. DataFrame SQL blocks can also be created by drag and dropping a CSV file from your filesystem (this also works for already uploaded files in the left sidebar). By executing that SQL block, the contents of the CSV file will be loaded into a DataFrame variable.
Here's an example of querying a DataFrame variabledf:
SELECT *
FROM df
and here's how we can query an existing CSV file:
SELECT *
FROM 'path/to/my_data.csv'
Data table output
When you execute a SQL query, Deepnote will display the result in a data table. The data table lets you get a sense of the data you're working with quickly through column descriptors such as breakdown of column values for categorical columns or summary statistics for numeric columns.
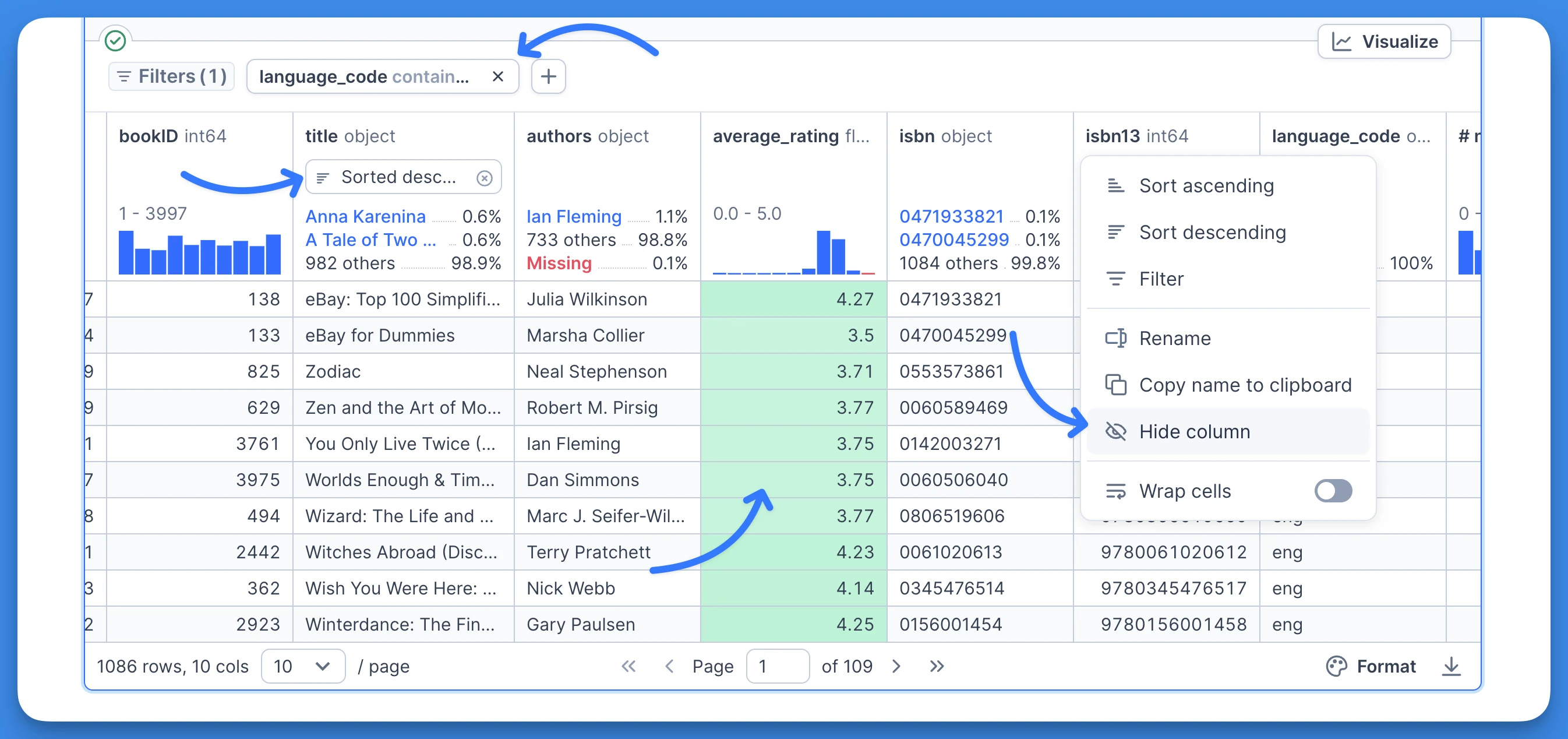
Have a look at the data table documentation for more details on how to further modify the data table through things like column filtering, column renaming or conditional cell formatting.
Output modes
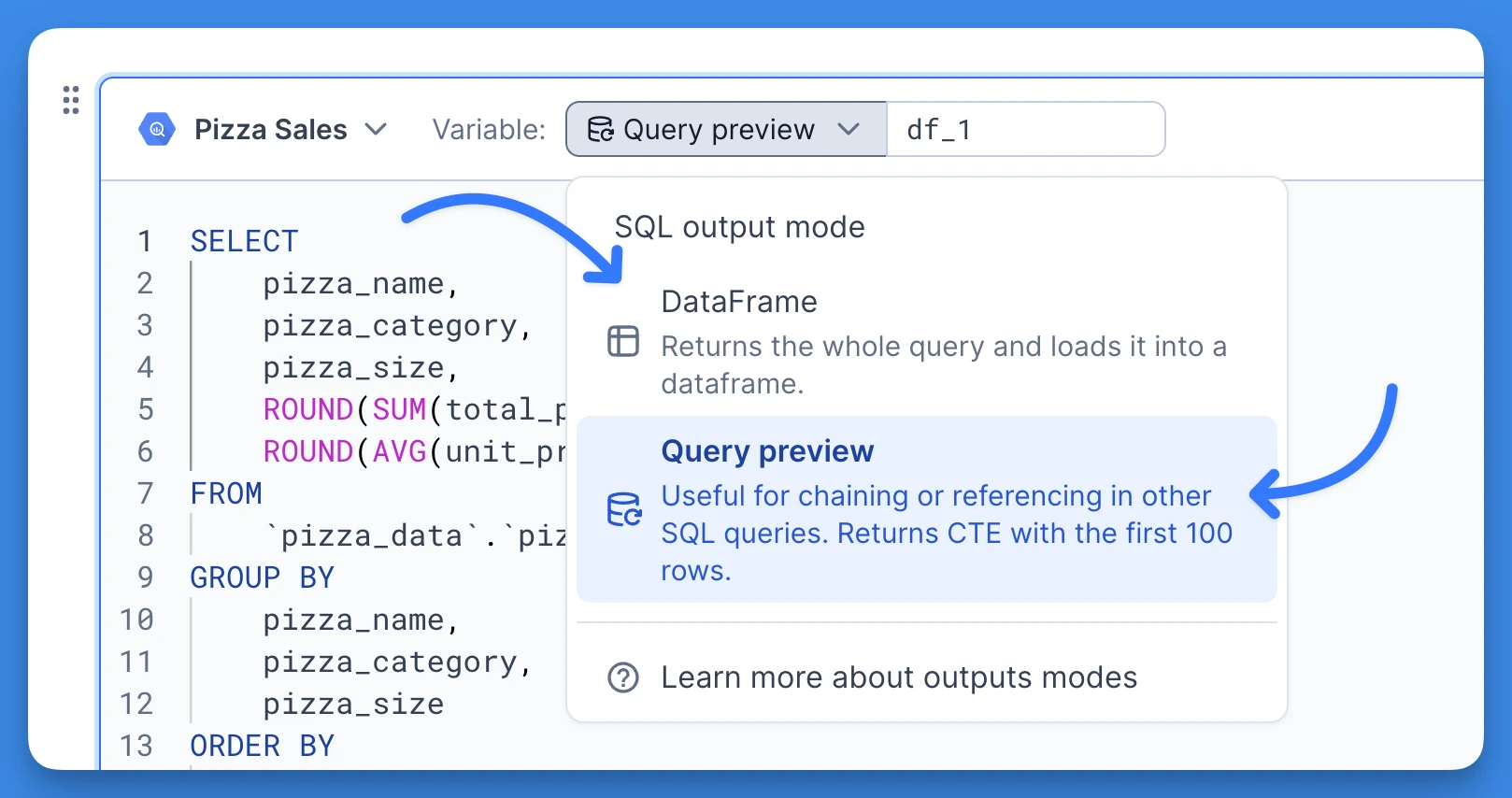
SQL blocks offer two distinct output modes: DataFrame mode and Query preview mode, each with its own use case.
- DataFrame
- By default, Deepnote saves the full results of executed queries into a Pandas DataFrame. In the above example, it's
df_1. You can use this variable for further processing in normal Python code blocks below.
- Query preview
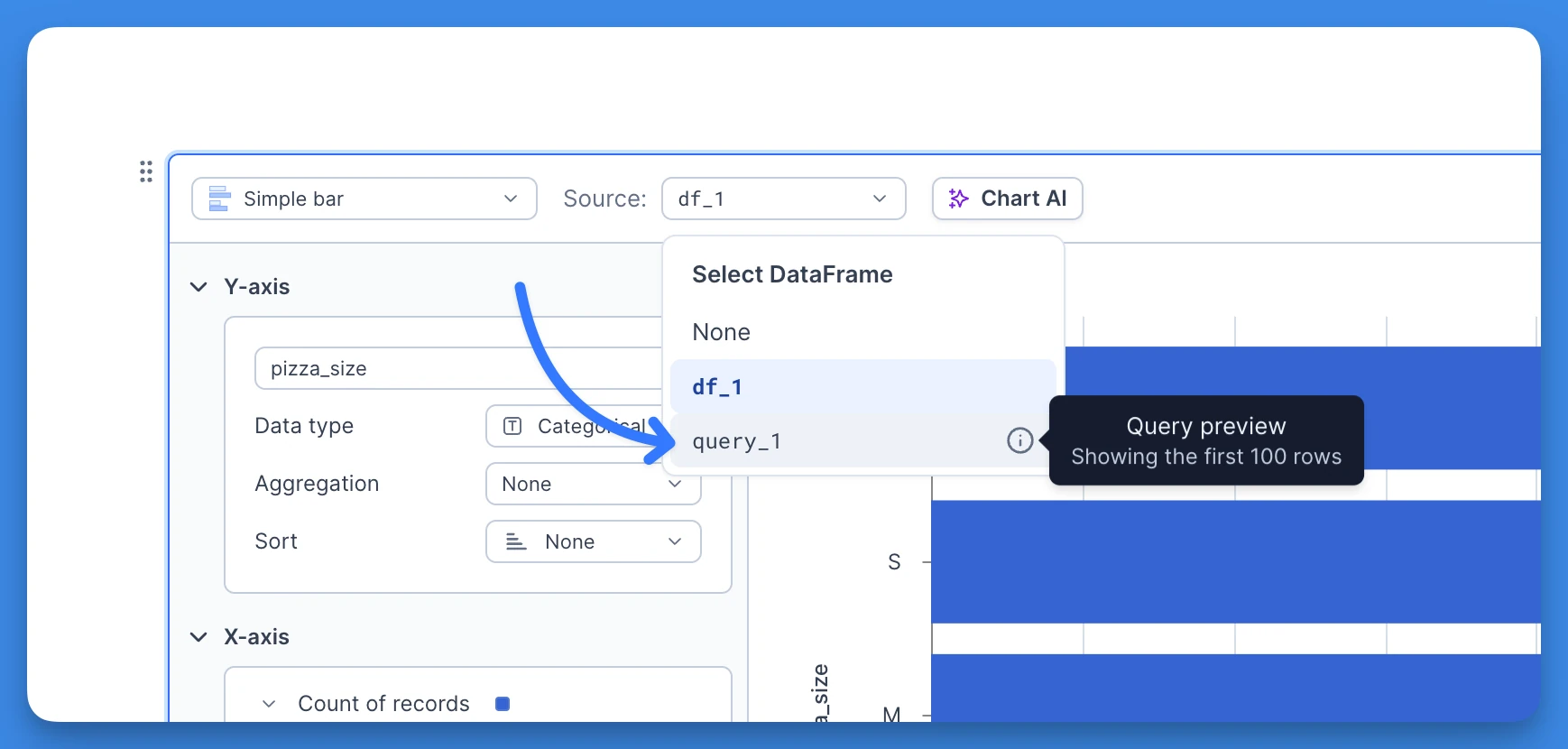
- Query preview mode, retrieves the first 100 rows of the result only, but instead of just creating a DataFrame, it will also store the source SQL code used to query that data. You can reference this query previews in your subsequent SQL blocks to build complex queries through query chaining. Using query preview mode let's you decide when to pull in the full results of the query into memory and leaving the data in the warehouse until then.
Q: When should I use query preview mode instead of DataFrame mode?
A: Use query preview mode when you want to defer from pulling data into memory or when you are building complex SQL queries that you want to test in iterations. Use DataFrame mode when you want to process the full results of a query at once.
Q: Can I reference DataFrame variables in SQL blocks?
A: No, you cannot reference DataFrame variables in SQL blocks. You can only reference query preview objects.
Q: Can I use query preview mode with DataFrame SQL blocks?
A: Yes! even though you are querying a DataFrame, you may want to retrieve only a subset of the data and reference the query later.
Q: Can I use query preview objects in other blocks?
A: Yes, you can use query previews exactly as you would use a DataFrame. Actually, the DeepnoteQueryPreview object that is returned is a subclass of a Pandas DataFrame. This means you can also plot it in a Chart block. However, do keep in mind that the preview only contains first 100 rows.
Query chaining
Query chaining makes complex SQL development simpler and more efficient. Instead of writing one massive query, you can break your logic into manageable steps across multiple blocks, using query preview to see results without loading entire datasets. Each query becomes a reusable building block that you can reference in subsequent SQL blocks. Behind the scenes, Deepnote automatically combines these references by generating proper CTE statements, giving you both the clarity of step-by-step development and the power of properly structured SQL. This approach makes your code easier to understand, debug, and maintain while keeping memory usage minimal
For example, let's say that we often query "large pizzas" from our Pizza Sales dataset. We can write a query and get back a preview of the first 100 results:
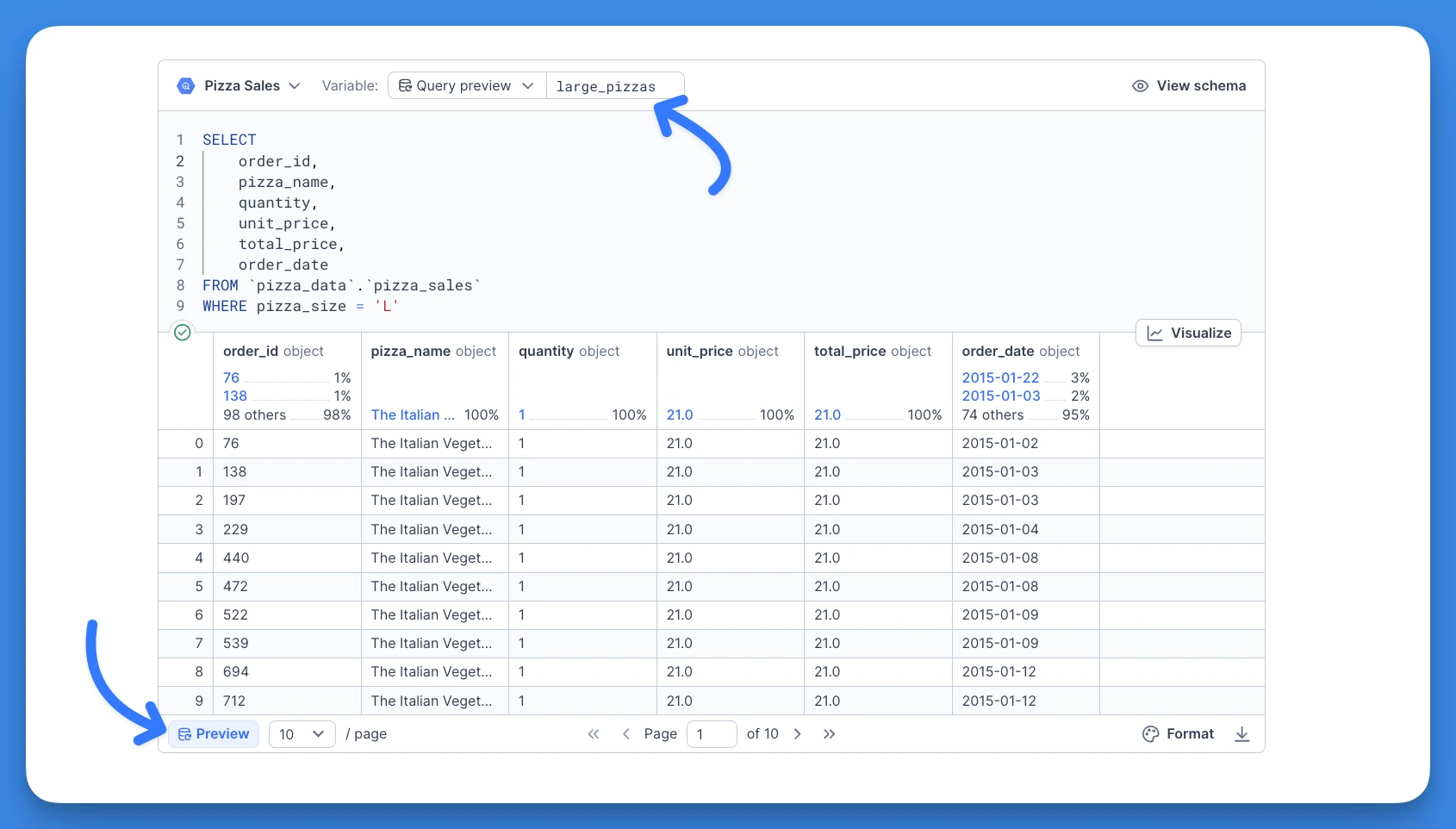
The result is stored as large_pizzas which can then be used downstream in another SQL block. Let's say that that we'd like to fetch some basic metrics for sales of large pizzas. We can reference the large_pizzas object as if it was a CTE:
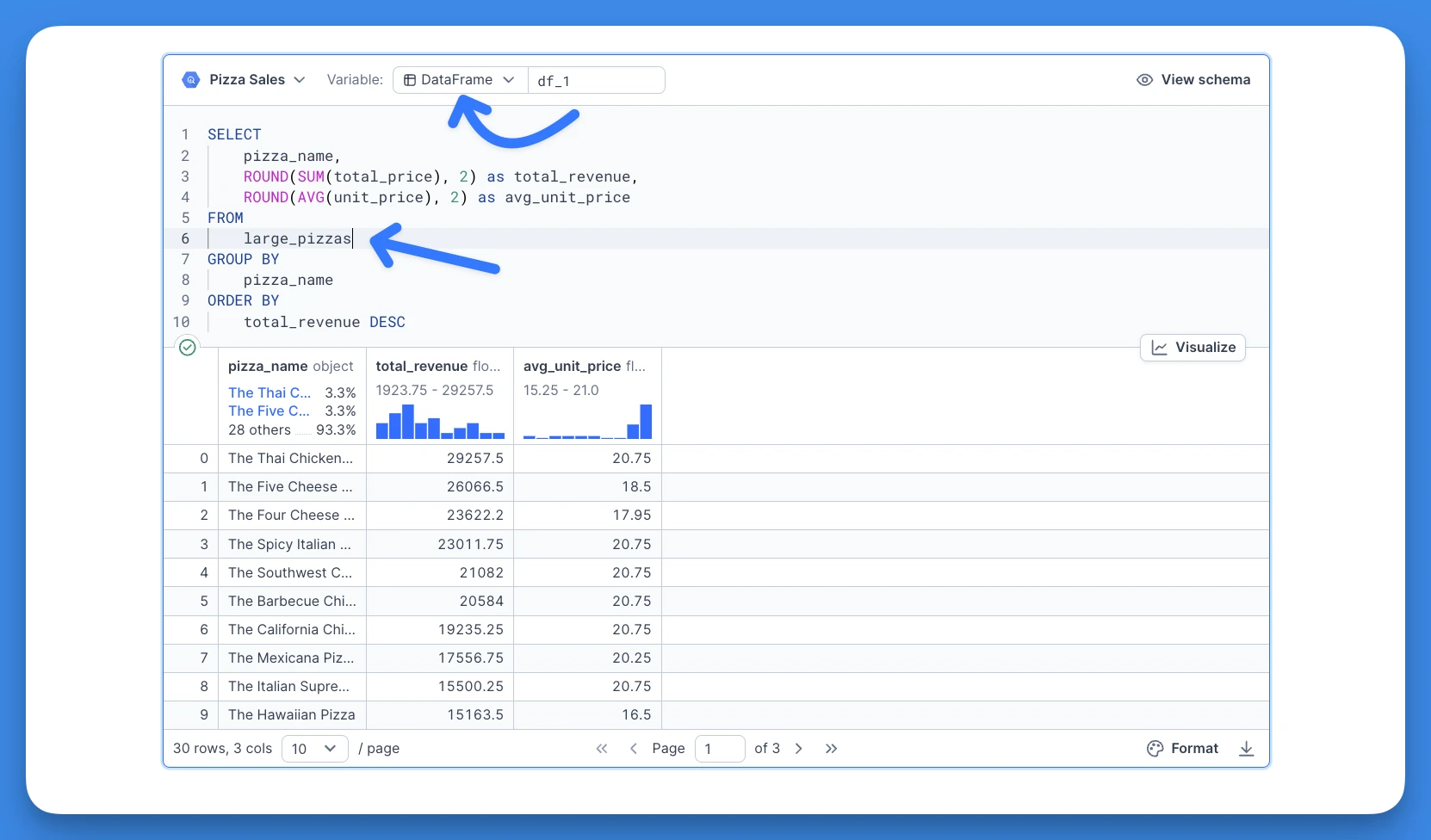
To inspect the compiled SQL query that get's executed, use the "Show compiled SQL query" in the block actions:
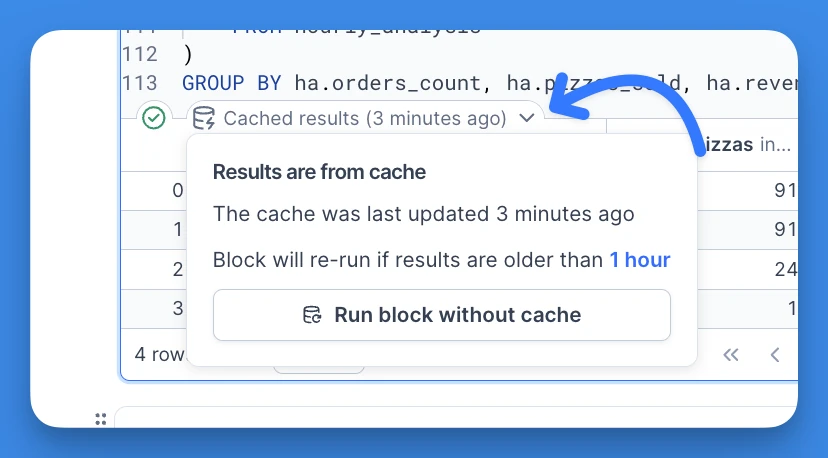
Query caching
With caching enabled, Deepnote automatically saves the results of your queries in SQL blocks. Returning these cached results for repeated queries can greatly improve performance in your notebooks and reduce the load on your database/warehouse. See Query caching for more information how to use and customize it to your needs.
SQL autocomplete
SQL blocks combine schema Intellisense autocompletions and inline AI completions together for seamless SQL writing.
The built-in Intellisense will offer relevant suggestions for your cursor position. This includes entities in your schema such as databases, tables or columns but also aliases, CTEs or query previews that you may have defined in your previous queries. The autocomplete will open automatically as you type. In addition to that, you can trigger it manually by using one of these keyboard shortcuts Control + Space, Option + Space or ⌘ + I.
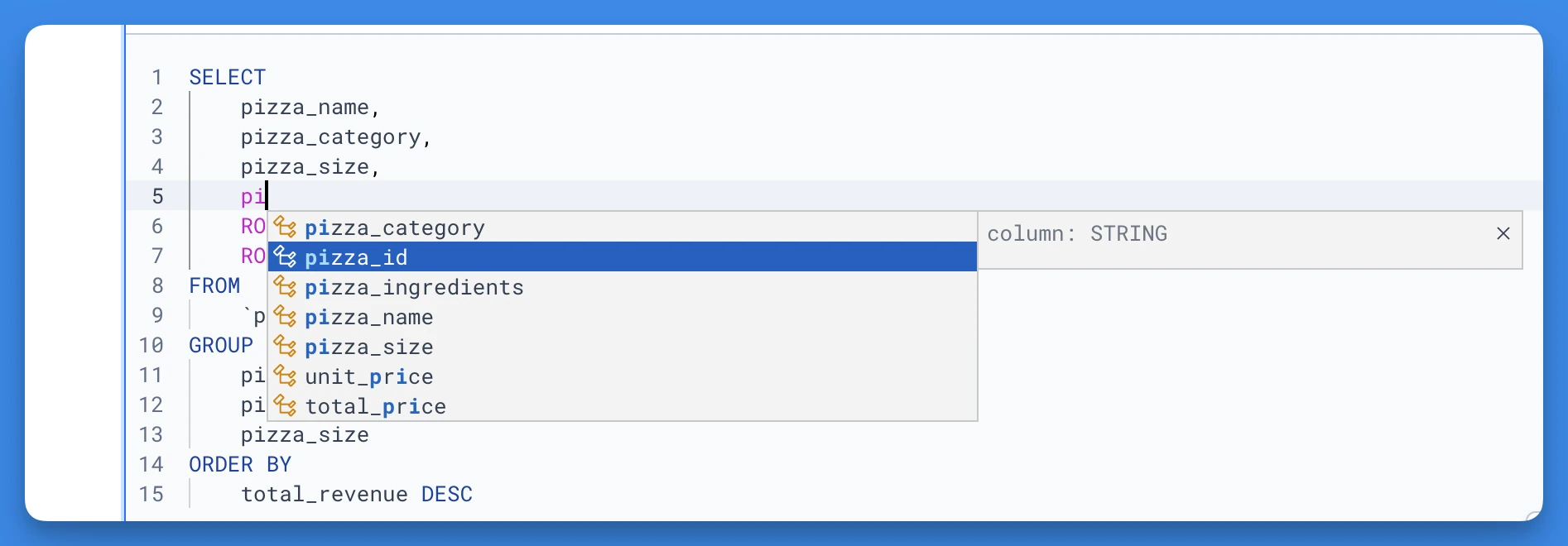
Generated AI completions fill in the gaps of schema completions by pulling in the context of your notebook as well as relevant SQL blocks from across your workspace to suggest outright entire SQL snippets.
Using Python and SQL together
Deepnote let's you seamlessly work with SQL and Python together. Results of SQL blocks generate DataFrames or query preview objects that you can further use in your Python code. However, you can also pass in your Python variables to SQL blocks. Deepnote uses jinjasql templating which allows you to pass variables, functions, and control structures (e.g., if statements and for loops) into your SQL queries.
- To inject a Python variable inside your SQL query use the
{{ variable_name }}syntax. For example:
SELECT date, name
FROM fh-bigquery.weather_gsod.all
WHERE name = {{ station_name }}
LIMIT 10
- Passing lists or tuples into your SQL queries requires the
inclausekeyword from jinjasql. As you can see below, we use a similar syntax as before but with this new keyword preceded by the|symbol.
SELECT date, name
FROM fh-bigquery.weather_gsod.all
WHERE name in {{ station_list | inclause}}
ORDER BY date DESC
- To inject column names and table names, use the
sqlsafekeyword as follows:
SELECT *
FROM {{ table_name | sqlsafe }}
- A common use-case is searching for a wildcard pattern containing (e.g., the
%character to represent optional substrings). To combine this with a variable value, use the following syntax:
SELECT *
FROM users
WHERE name LIKE {{ '%' + first_name + '%' }}
- You can also use more advanced templating features like
{% if condition } %{ endif }, conditional blocks, or anything else that's supported by jinjasql. For example, the following block loops through a Python list (column_names) to construct the desired SQL fields.
SELECT date, name,
{% raw %}
{% for col in column_names %}
{% if not loop.last %}
{{ col | sqlsafe }},
{% else %}
{{ col | sqlsafe }}
{% endif %}
{% endfor %}
{% endraw %}
FROM fh-bigquery.weather_gsod.all
WHERE date > '2015-12-31'
AND name = {{ station_name }}
ORDER BY date DESC
LIMIT 5
Handling empty input values in SQL blocks
In some instances, you may want to use an input value that can be empty in a SQL block. For example, you might want to give the user the ability optionally filter a table. In those instances, you need to handle Null values in your SQL blocks. Here are two practical approaches:
- Using JinjaSQL conditional blocks This approach is particularly useful when you want to conditionally include entire SQL clauses:
SELECT signup_date, name
FROM users
{% if start_date %}
WHERE signup_date >= {{ start_date }}
{% endif %}
- Using SQL's native NULL handling This approach leverages SQL's built-in NULL handling capabilities, which can be more concise when dealing with simple conditions:
SELECT signup_date, name
FROM users
WHERE signup_date >= {{ start_date }}
OR {{ start_date }} IS NULL