Exploring JAX
Exploring JAX
JAX is a linear algebra library that's quick for numerical computations on high-end machines like GPUs and TPUs. Python already has a great XLA (accelerated linear algebra) library named NumPy. The code snippets below show examples for both NumPy and JAX. In the article below, the core features of JAX are explained in

For more information on setup and installation, here is the link to the official JAX website.

XLA, automatic differentiation, and just-in-time compilation
The title JAX came from:
- XLA (Accelerated linear algebra): JAX uses XLA, Google’s optimized compiler for linear algebra, to speed up calculations and make it run efficiently on different hardware.
- A (Autograd): JAX was originally built by the Autograd library and can automatically calculate derivatives. This makes it perfect for tasks like optimization, neural networks, and machine learning, as it helps compute how functions change, enabling gradient-based optimization.
- JIT(Just-in-time compilation): In JAX, functions are converted into basic operations (JAXPR) and evaluated like a small functional programming language. Here's an example of how JAX transforms a simple function:
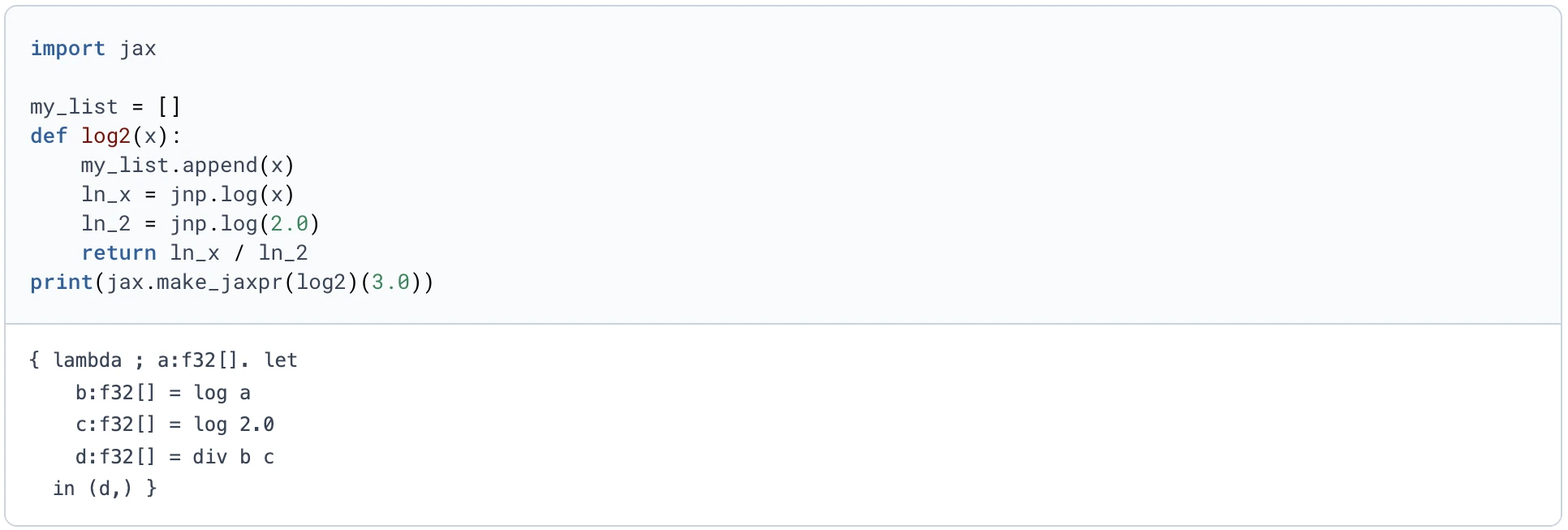
Get started
The JAX can be installed based on the target hardware:
pip install "jax[cpu]"
pip install "jax[cuda12]" # For Nvidia GPUs
pip install "jax[tpu]" # For TPUs
Each installation customize JAX to use device's strengths. The cuda12 option is for Nvidia GPU users, while tpu is for Tensor processing units.
Example: immutable arrays in JAX
Unlike NumPy, JAX uses immutable arrays. For instance, when the array element is updated, to set values the .at[] is used to set values in a new array, preserving the original:

Automatic differentiation in JAX
Automatic differentiation (AD) is useful in real-world applications because it quickly calculates gradients, which are key for optimization and machine learning. In machine learning, JAX automates this process, speeding up model training and eliminating the need for manually computing derivatives, making it ideal for complex tasks like neural networks and scientific simulations.
For instance, a Python function could compute the height of a physical system at a specific time, whereas JAX’s grad function facilitates automatic differentiation to determine the rate of change.

The grad function can also handle arrays, producing a gradient array with partial derivatives. Because grad itself returns a function, it can be applied it multiple times to get higher-order derivatives, making it essential in complex machine learning and optimization.
Real-world example: modeling population growth
JAX’s automatic differentiation excels at modeling dynamic systems, especially those where tracking the change of parameters over time is essential. For instance, considering modeling the growth of a city’s population over time. A function might be created to estimate the population at any given year, but it can also be essential to know the growth rate at specific points to make predictions or policy decisions.
Using JAX’s grad, one can differentiate this function to understand how fast the population is growing at any given time. If the function is adapted to accept a range of parameters (such as birth rate, death rate, migration rate), grad will return an array of partial derivatives, each representing the effect of one variable on the growth rate.
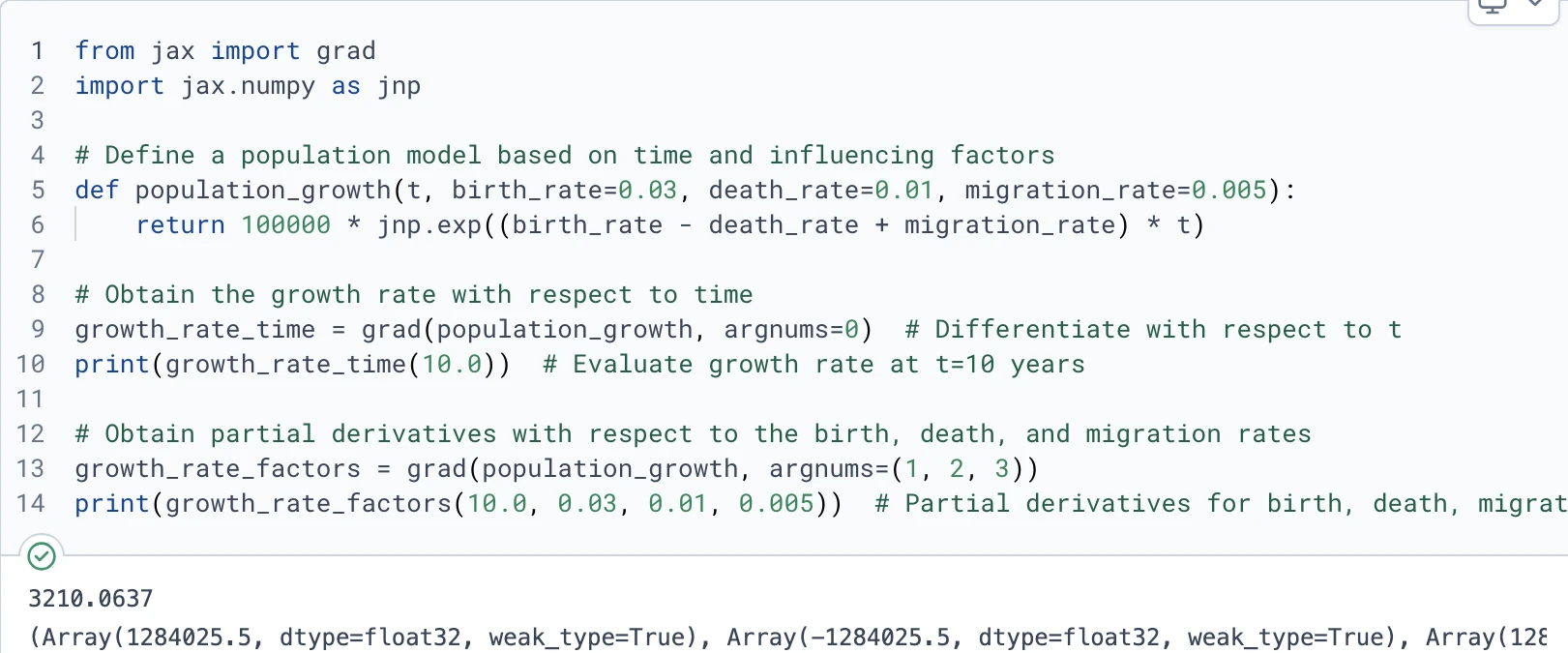
Gradients are essential in machine learning, where they guide adjustments to model parameters, helping decrease error rates and improve performance. With libraries like Flax and nnx built on JAX, it’s possible to create neural networks that automatically use this gradient-based optimization for faster, more efficient training.
Next steps for learning more
-
Explore the official JAX websites.
-
Here is the data app, where the real-life use of JAX can be explored.
-
Here is a comparison of JAX vs. PyTorch.